XGBoost Classifier
XGBoost (eXtreme Gradient Boosting) is a powerful and widely-used gradient boosting algorithm that is used to solve many different types of machine learning problems. It is an implementation of gradient boosting that is specifically designed to be efficient and scalable, making it a popular choice for working with large datasets.
Mathematically, XGBoost is an ensemble learning method that combines the predictions of multiple weak models to produce a strong prediction. The weak models in XGBoost are decision trees, which are trained using gradient boosting. This means that at each iteration, the algorithm fits a decision tree to the residuals of the previous iteration.
The decision trees in XGBoost are trained using the following objective function:
$$\min_{\theta} \left(\sum_{i=1}^n l(y_i, \hat{y}_i) + \sum_{k=1}^K \Omega(f_k)\right)$$
where l is the loss function, yi is the true label of the ith training example, `\hat{y}_i` is the predicted label of the ith training example, fk is the kth decision tree, and `\Omega` is a regularization term that penalizes the complexity of the trees. This objective function is optimized using gradient descent.
Once the decision trees have been trained, XGBoost makes predictions by combining the predictions of all the trees using a weighted average. The weights for each tree are learned during training using the same objective function. This allows the algorithm to automatically learn which trees are more important and should be given more weight in the final prediction.
XGBoost is a multi-platform gradient boosting package that implements a gradient boosting framework. The algorithm is scalable for parallel computing. In addition to Python, it is available in C++, Java, R, Julia, and other computational languages. XGBoost has gained attention in machine learning competitions as an algorithm of choice for classification and regression.

Advantages: Effective with large data sets. Tree algorithms such as XGBoost and Random Forest do not need normalized features and work well if the data is nonlinear, non-monotonic, or with segregated clusters.
Disadvantages: Tree algorithms such as XGBoost and Random Forest can over-fit the data, especially if the trees are too deep with noisy data.
| Hyperparameter | Description | Typical range/values |
|---|---|---|
n_estimators |
Number of boosting rounds (trees). More estimators improve performance up to a point but increase training time. | 100 – 500 (tune up to 1000) |
learning_rate (eta) |
Step size shrinkage used to prevent overfitting. Lower values require more trees. | 0.01 – 0.2 |
max_depth |
Maximum depth of each tree. Controls complexity. | 3 – 10 |
min_child_weight |
Minimum sum of instance weight (hessian) needed in a child. Higher values prevent overfitting. | 1 – 10 |
subsample |
Fraction of observations randomly sampled for each tree. | 0.5 – 1.0 |
colsample_bytree |
Fraction of features sampled for each tree. | 0.5 – 1.0 |
gamma |
Minimum loss reduction required to make a split; acts as a regularization term. | 0 – 5 |
lambda (reg_lambda) |
L2 regularization term on weights. | 0 – 1 (often default 1) |
alpha (reg_alpha) |
L1 regularization term on weights. | 0 – 1 |
xgbc = xgb.XGBClassifier()
xgbc.fit(XA,yA)
yP = xgbc.predict(XB)
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.model_selection import train_test_split
# define dataset
X, y = make_classification(n_samples=1000, n_features=10, n_informative=8)
Xa,Xb,ya,yb = train_test_split(X, y, test_size=0.2, shuffle=True)
xgbc = xgb.XGBClassifier()
xgbc.fit(Xa,ya)
yp = xgbc.predict(Xb)
acc = accuracy_score(yb,yp)
print(acc)
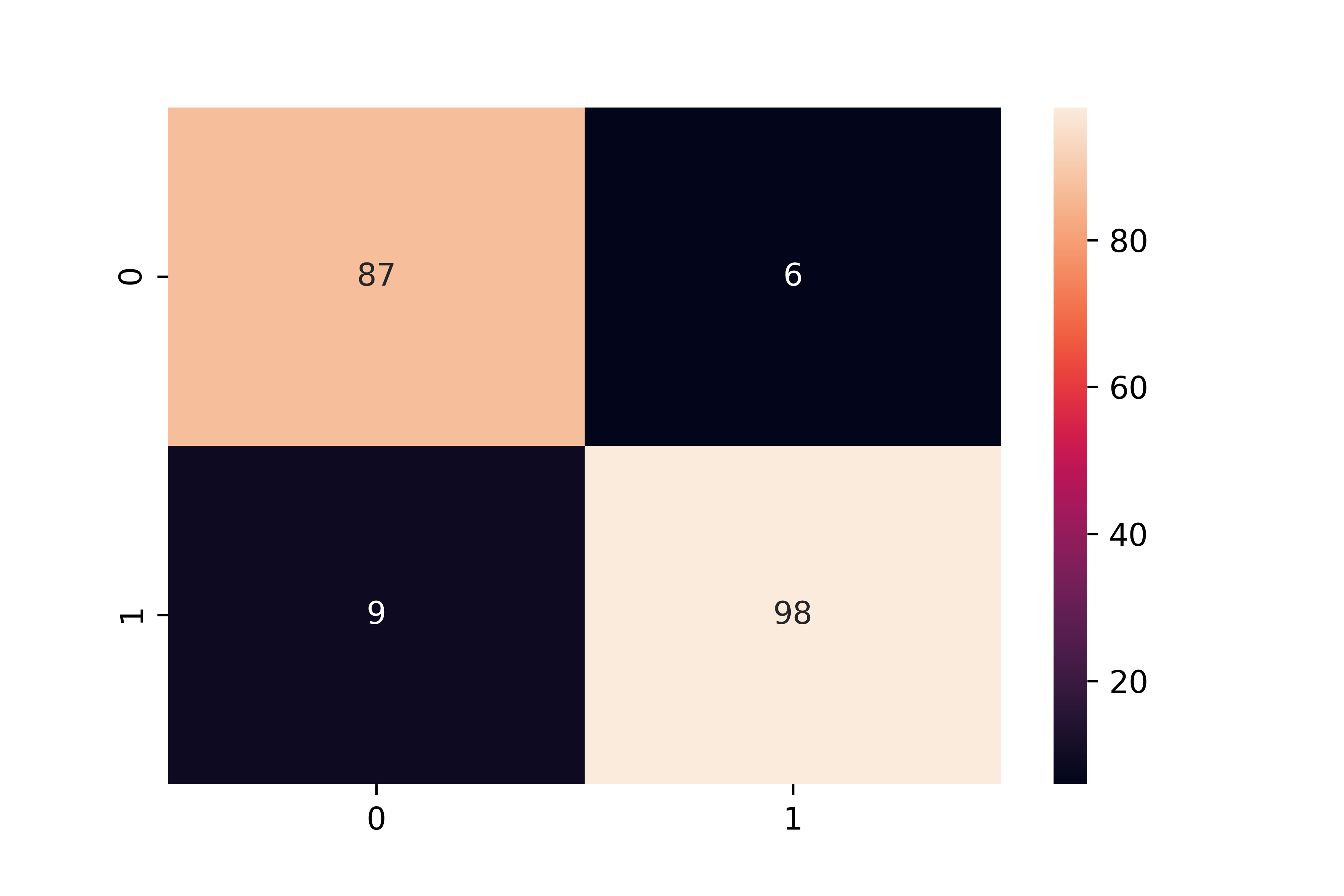
cm = confusion_matrix(yp,yb)
sns.heatmap(cm,annot=True)
plt.show()
Optical Character Recognition with XGBoost

In the context of optical character recognition (OCR), XGBoost could be used to train a model to recognize characters in images of text.
Here is an example of using XGBoost for OCR in Python:
import numpy as np
from sklearn.datasets import load_digits
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
# Load the dataset of images of handwritten digits
digits = load_digits()
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(digits.data,
digits.target,
random_state=0)
# Create an XGBoost classifier
clf = XGBClassifier()
# Train the model using the training set
clf.fit(X_train, y_train)
# Evaluate the model's performance on the test set
accuracy = clf.score(X_test, y_test)
print("Accuracy: %0.2f" % accuracy)
In this example, we use the scikit-learn and xgboost libraries to load the dataset of images of handwritten digits, split the dataset into training and testing sets, and train an XGBoost classifier. We then evaluate the model's performance on the test set by computing the accuracy, which is the proportion of test images that the model correctly identifies. See an additional example below that also displays a test digit.
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import xgboost as xgb
classifier = xgb.XGBClassifier()
# The digits dataset
digits = datasets.load_digits()
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
# Split into train and test subsets (50% each)
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.5, shuffle=False)
# Learn the digits on the first half of the digits
classifier.fit(X_train, y_train)
# Test on second half of data
n = np.random.randint(int(n_samples/2),n_samples)
print('Predicted: ' + str(classifier.predict(digits.data[n:n+1])[0]))
# Show number
plt.imshow(digits.images[n], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
MATLAB Live Script

✅ Knowledge Check
1. Which of the following is NOT a characteristic of XGBoost?
- Incorrect. XGBoost is indeed an ensemble learning method that combines the predictions of multiple decision trees.
- Correct. One of the advantages of tree algorithms like XGBoost is that they do not need normalized features.
- Incorrect. XGBoost is specifically designed to be efficient and scalable, especially with large datasets.
- Incorrect. The weak models in XGBoost are indeed decision trees.
2. How does XGBoost make final predictions?
- Incorrect. XGBoost combines the predictions of all trees using a weighted average.
- Incorrect. XGBoost does not make predictions based on a single random tree.
- Incorrect. XGBoost combines the predictions of all trees, not just the first and last.
- Correct. XGBoost makes predictions by combining the predictions of all the trees using a weighted average.
See also XGBoost Regressor
Return to Classification Overview
