Naive Bayes
Naïve Bayes classification is a machine learning algorithm that uses Bayes' theorem to make predictions. The theorem is based on the idea that the predictors are independent of each other. In other words, the value of one predictor is not related to the value of any other predictor.
Bayes' theorem is a mathematical equation that describes the relationship between the probability of an event and the conditional probability of another event. It is typically expressed as follows:
P(A|B) = P(B|A) * P(A) / P(B)
where P(A|B) is the conditional probability of event A occurring given that event B has already occurred, P(B|A) is the conditional probability of event B occurring given that event A has already occurred, P(A) is the probability of event A occurring, and P(B) is the probability of event B occurring.
In the context of Naïve Bayes classification, we can use Bayes' theorem to calculate the probability that an input belongs to a particular class, given the values of the input's predictors. For example, suppose we have a dataset containing information about different types of animals. We could use Naïve Bayes classification to predict the type of animal based on its color and size.
Naïve Bayes algorithm is based on Bayes’ theorem with the assumption of independence between every pair of features. Naive Bayes classifiers work well in many real-world situations such as document classification and spam filtering. It works well with large and high-dimensional data sets, especially when there is at least one feature that is a strong predictor of each class.
Advantages: This algorithm requires a small amount of training data to estimate the necessary parameters. Naive Bayes classifiers are extremely fast compared to more sophisticated methods.
Disadvantages: Naïve Bayes is known to be a bad estimator, but it may be the best option given the favorable training speed, low memory requirement, and fast predictions.
Python Sample Code
nb = GaussianNB()
nb.fit(XA,yA)
yP = nb.predict(XB)
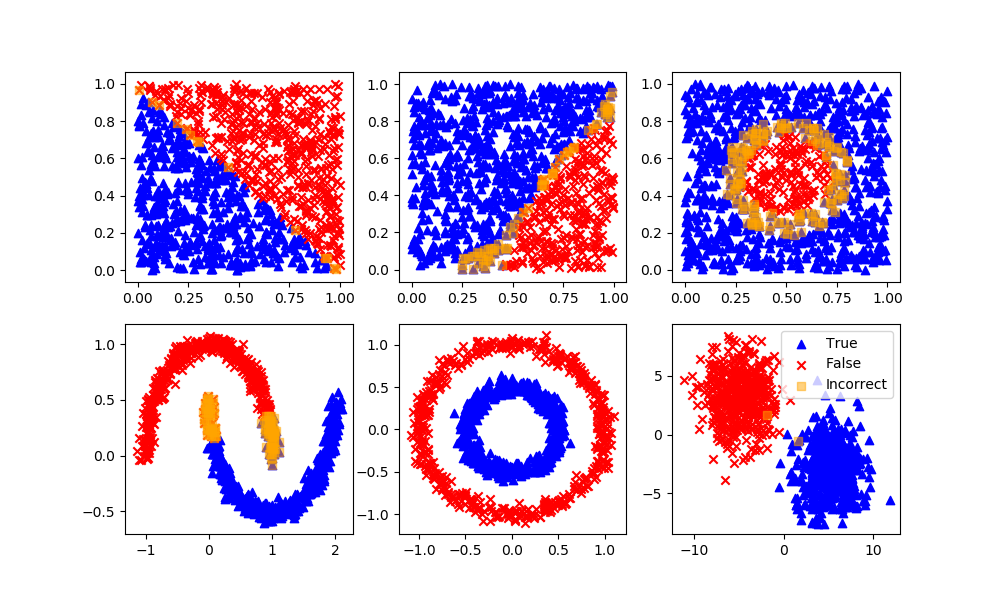
Optical Character Recognition with Naïve Bayes in Python

Optical character recognition (OCR) is a technology that enables the recognition of text characters in digital images. This technology can be used to automatically convert scanned documents, pictures, or other digital images that contain text into machine-readable text.
Naïve Bayes is a type of machine learning algorithm that is commonly used in the field of OCR. This algorithm is based on the idea of using Bayes' theorem to make predictions about the likelihood of different outcomes based on the available data.
In the context of OCR, a Naive Bayes classifier can be trained to recognize text characters in images by learning from a large dataset of labeled images. The classifier uses Bayes' theorem to calculate the likelihood that a given image contains each of the possible text characters, and then makes a prediction about which character is most likely to be present in the image. Here is an incomplete example of how this might be implemented in Python:
from sklearn.naive_bayes import GaussianNB
# Create a Gaussian Naive Bayes classifier
classifier = GaussianNB()
# Train the classifier using labeled data
classifier.fit(X, y)
# Use the classifier to make predictions on new data
predictions = classifier.predict(X_test)
In this code, the GaussianNB class from the sklearn.naive_bayes library is used to create a Gaussian Naive Bayes classifier. The classifier is then trained on a dataset of labeled images (represented by the X and y variables) using the fit method. Finally, the classifier can be used to make predictions on new data (represented by the X_test variable) using the predict method. Below is a complete example with a train/test split.
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
# The digits dataset
digits = datasets.load_digits()
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
# Split into train and test subsets (50% each)
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.5, shuffle=False)
# Learn the digits on the first half of the digits
classifier.fit(X_train, y_train)
# Test on second half of data
n = np.random.randint(int(n_samples/2),n_samples)
print('Predicted: ' + str(classifier.predict(digits.data[n:n+1])[0]))
# Show number
plt.imshow(digits.images[n], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
MATLAB Live Script

✅ Knowledge Check
1. Which of the following is a correct interpretation of Bayes' theorem?
- Incorrect. This interpretation reverses the conditional relationship. The correct interpretation of P(A|B) is the probability of event A occurring given that event B has already occurred.
- Correct. This is the correct formulation of Bayes' theorem.
- Incorrect. Bayes' theorem itself does not make this assumption. However, the Naïve Bayes classifier assumes predictors are independent of each other.
- Incorrect. Naïve Bayes uses Bayes’ theorem with the assumption of independence between every pair of features.
2. Why is the Naïve Bayes classifier considered "naive"?
- Incorrect. The "naive" in Naïve Bayes refers to the assumption that all predictors are independent of each other.
- Incorrect. While Naïve Bayes is relatively simple, the term "naive" refers to its assumption about predictor independence, not its simplicity.
- Correct. The "naive" in Naïve Bayes refers to this assumption.
- Incorrect. Despite its simplicity, Naïve Bayes is still widely used in various applications like document classification and spam filtering due to its efficiency.
Return to Classification Overview
