k-Nearest Neighbors Classifier
Neighbors based classification is a type of lazy learning as it does not attempt to construct a general internal model, but simply stores instances of the training data. Classification is computed from a simple majority vote of the k nearest neighbors of each point. Specifically, k-Nearest Neighbors (kNN) is a type of instance-based learning or non-parametric learning algorithm, where the model is not explicitly trained, but instead makes predictions by comparing new data points to the nearest neighbors in the training data. The algorithm works by calculating the distances between the new data point and the training data, selecting the k-nearest data points, and then making a prediction based on the class or label of the selected neighbors.
Advantages: This algorithm is simple to implement, robust to noisy training data, and effective if training data is large.
Disadvantages: Need to determine the value of k and the computation cost is high as it needs to computer the distance of each instance to all the training samples. A feedback loop can be added to determine the number of neighbors.
k-Nearest Neighbors in Python
Here is an example of k-nearest neighbors in Python using the scikit-learn library:
# Create a k-nearest neighbors classifier with 3 neighbors
model = KNeighborsClassifier(n_neighbors=3)
# Train the model on the training data
model.fit(X_train, y_train)
# Make predictions on the test set
y_pred = model.predict(X_test)
In this example, we first create a k-nearest neighbors classifier with 3 neighbors using the KNeighborsClassifier class from scikit-learn. Then, we train the model on the training data using the fit method. Finally, we use the trained model to make predictions on the test set using the predict method. The number of neighbors is the hyperparameter for tuning the performance. Change n_neighbors to a higher number to gain more consensus for the classification.
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(XA,yA)
yP = knn.predict(XB)
Optical Character Recognition with k-Nearest Neighbors

Optical character recognition (OCR) is the process of extracting text from images or scanned documents. OCR algorithms are typically based on machine learning models that are trained on large datasets of images containing text.
Here is an example of OCR using a k-nearest neighbors (kNN) classifier in Python using the scikit-learn library:
from sklearn.datasets import load_digits
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# Load the dataset of images of handwritten digits
digits = load_digits()
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(digits.data,
digits.target,
random_state=0)
# Create a k-nearest neighbors classifier with 3 neighbors
model = KNeighborsClassifier(n_neighbors=3)
# Train the model using the training set
model.fit(X_train, y_train)
# Evaluate the model's performance on the test set
accuracy = model.score(X_test, y_test)
print("Accuracy: %0.2f" % accuracy)
In this example, we first load the digits dataset from scikit-learn, which contains images of handwritten digits. Then, we create a k-nearest neighbors classifier with 3 neighbors using the KNeighborsClassifier class. Next, we train the model on the digits dataset. Finally, we use the trained model to make predictions on new images.
Note that this is just a simple example of OCR using a kNN classifier in scikit-learn, and many other more advanced OCR algorithms and libraries exist. kNN classifiers may not be the most effective model for OCR tasks, as they are not well-suited to high-dimensional datasets like images. Below is a complete example with a train/test dataset split.
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=5)
# The digits dataset
digits = datasets.load_digits()
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
# Split into train and test subsets (50% each)
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.5, shuffle=False)
# Learn the digits on the first half of the digits
classifier.fit(X_train, y_train)
# Test on second half of data
n = np.random.randint(int(n_samples/2),n_samples)
print('Predicted: ' + str(classifier.predict(digits.data[n:n+1])[0]))
# Show number
plt.imshow(digits.images[n], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()


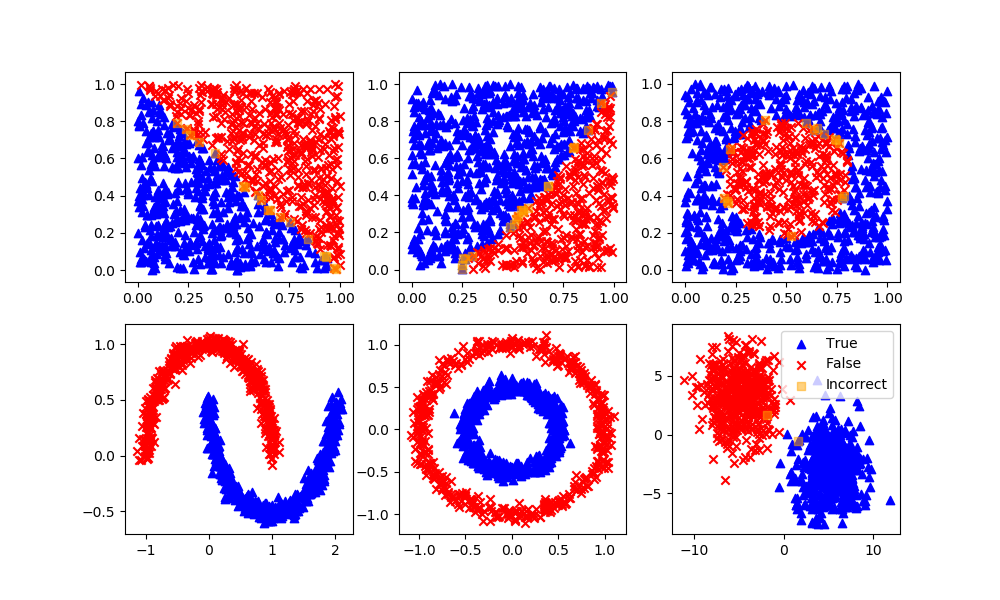
k-Nearest Neighbors for Animal Classification
It is proposed to classify cats and dogs by weight. A total of 16 animals are measured and the data is split into a test (3) and train (13) set.
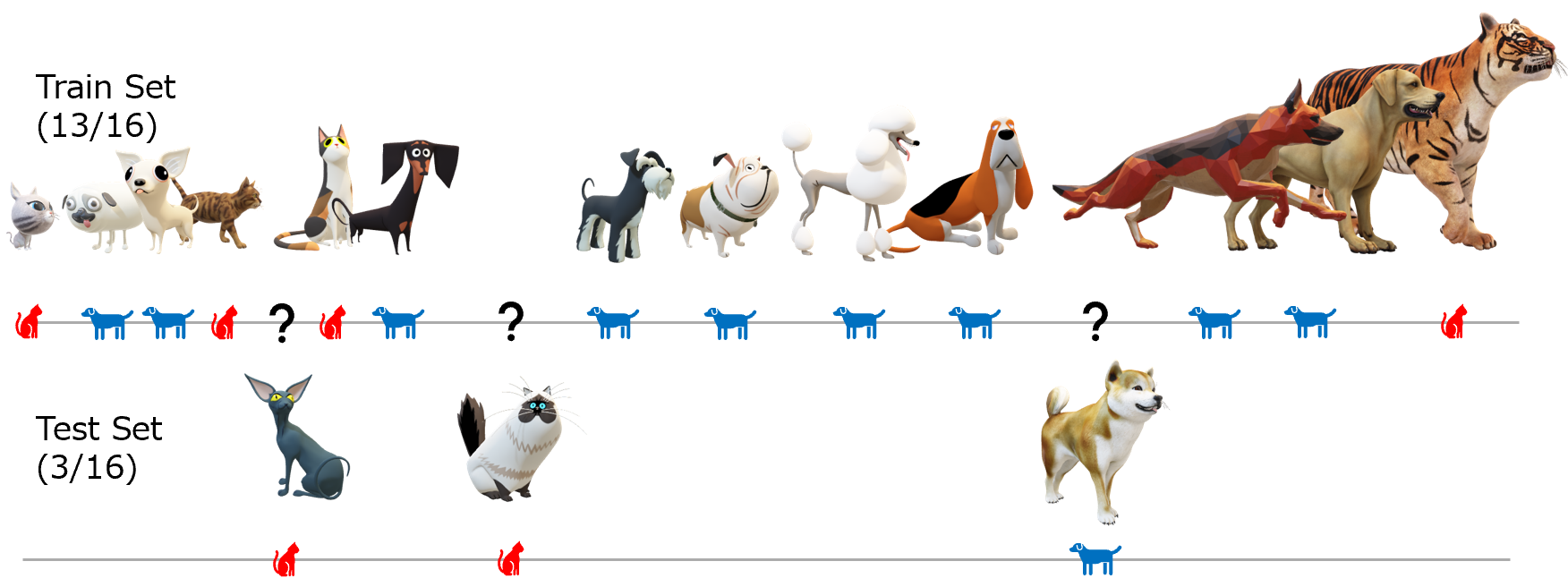
The accuracy of the classifier is defined as the number of correct test classifications divided by the total number in the test set.
$$Accuracy = \frac{Correct}{Total} \mathrm{x} 100\%$$
What is the accuracy of the dog and cat classifier with k=2?
Solution Help
k-Nearest Neighbors Programmming
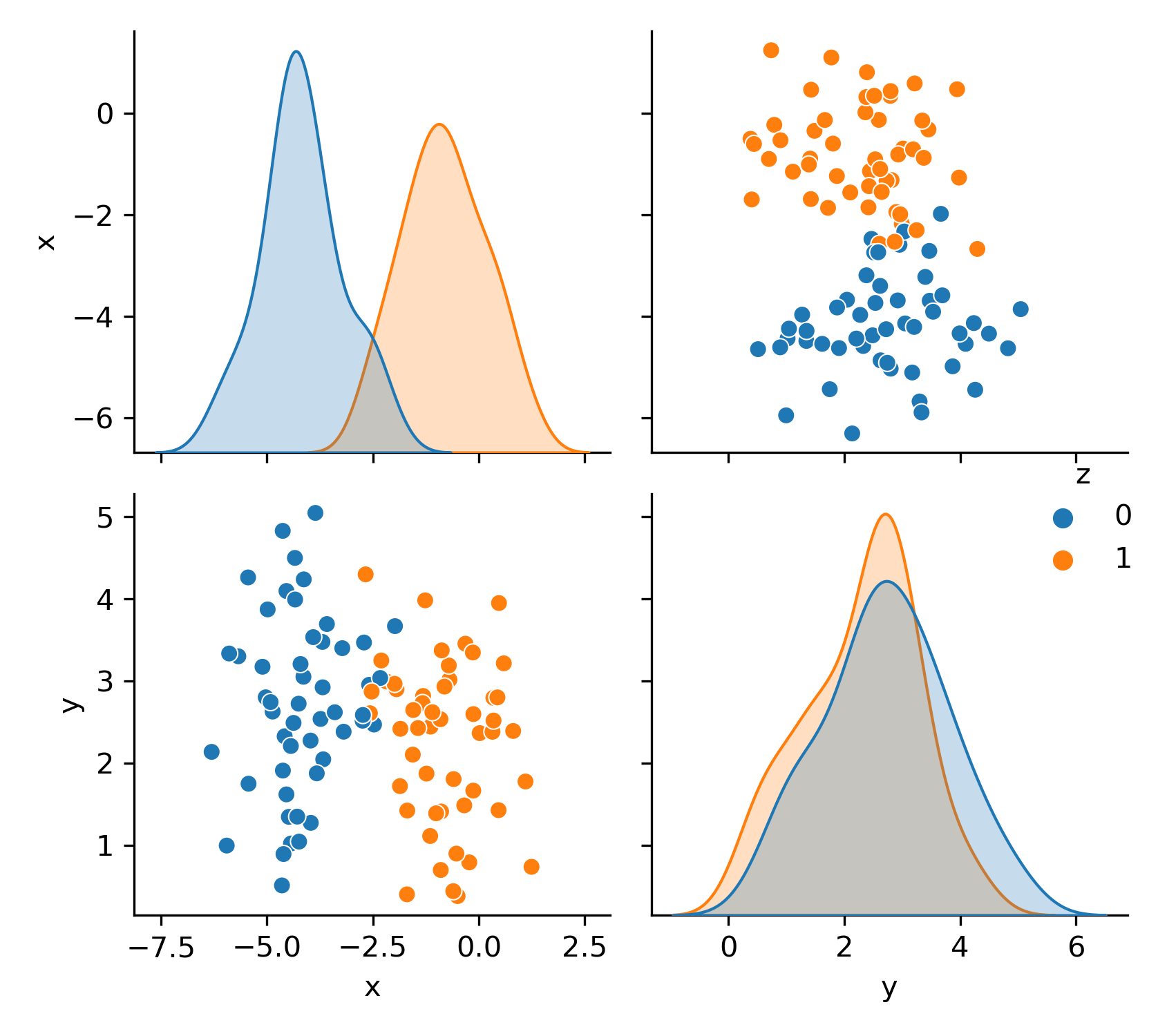
Using only Python code (not a machine learning package), create a k-Nearest Neighbors classifier. Use the blobs test code to evaluate the performance of the code.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_blobs
n_samples = 100
features, label = make_blobs(n_samples=n_samples, centers=2,\
n_features=2,random_state=7,
cluster_std=1.0, center_box=(-5.0, 5.0))
data = pd.DataFrame({'x':features[:,0],'y':features[:,1],\
'z':label})
sns.pairplot(data,hue='z')
Resources
- k-nearest neighbors on Wikipedia, retrieved 29 Jan 2021.
- Brownlee, J., Develop k-Nearest Neighbors in Python From Scratch, Machine Learning Mastery, Retrieved 29 Jan 2021.
Solutions
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_blobs
n_samples = 100
features, label = make_blobs(n_samples=n_samples, centers=2,\
n_features=2,random_state=7,
cluster_std=1.0, center_box=(-5.0, 5.0))
data = pd.DataFrame({'x':features[:,0],'y':features[:,1],\
'z':label})
# split data
train = data[0:70].copy()
test = data[70:].copy().reset_index(drop=True)
# evaluate on test data
k = 3 # k=3 Nearest Neighbors
correct = 0
train['dist'] = 0
for s in range(len(test)):
x,y,z = test.iloc[s]
train['dist'] = np.sqrt((train['x']-x)**2 \
+(train['y']-y)**2)
train = train.sort_values('dist')
if int(train['z'].iloc[0:k].median())==int(z):
correct += 1
print(f'Correct: {100*correct/len(test)}%')


✅ Knowledge Check
1. Which statement best describes k-Nearest Neighbors (kNN) algorithm?
- Incorrect. kNN is a type of lazy learning, which means it doesn't construct a general internal model but makes predictions based on the training data instances.
- Incorrect. While kNN is a type of supervised learning, it is not explicitly trained using a training dataset in the traditional sense. It relies on instance-based or non-parametric learning.
- Correct. The kNN algorithm works by calculating distances between a new data point and existing training data points and then makes a decision based on the majority vote from the nearest neighbors.
- Incorrect. The number of neighbors, represented by 'k', is a hyperparameter in kNN that determines how many nearest neighbors will be considered when making a classification.
2. In the given Python example of kNN using the scikit-learn library for OCR, how many neighbors are used for classification?
- Incorrect. In the provided OCR example, the number of neighbors specified is 3, not 5.
- Incorrect. In the provided OCR example, the number of neighbors specified is 3.
- Correct. In the provided OCR example, the KNeighborsClassifier is created with n_neighbors=3, which means it uses 3 neighbors for classification.
- Incorrect. While it's possible to use techniques to dynamically determine the best 'k', in the provided example, it is explicitly set to 3.
See also k-Nearest Neighbors for Regression
Return to Classification Overview

