Gaussian Mixture Model



A Gaussian mixture model (GMM) is a probabilistic model that assumes that the data it is modeling is generated by a mixture of multiple Gaussian distributions. This means that each data point is assumed to come from one of the Gaussian distributions, and the probability of a data point coming from a particular distribution is given by a weight.
Mathematically, a GMM with K Gaussian distributions is defined as follows:
$$p(x | \theta) = \sum_{k=1}^K \pi_k \mathcal{N}(x | \mu_k, \Sigma_k)$$
where `\theta = { \pi_1, \ldots, \pi_K, \mu_1, \ldots, \mu_K, \Sigma_1, \ldots, \Sigma_K }` is the set of parameters of the model, `\pi_k` is the weight of the kth Gaussian distribution, `\mu_k` is the mean vector of the kth Gaussian distribution, and `\Sigma_k` is the covariance matrix of the kth Gaussian distribution. The term `\mathcal{N}(x | \mu_k, \Sigma_k)` is the probability density function (PDF) of the kth Gaussian distribution.
Given a dataset, the goal of fitting a GMM is to find the values of `\theta` that maximize the likelihood of the data. This can be done using the expectation-maximization (EM) algorithm, which is an iterative algorithm that alternates between two steps:
- E-step: Given the current values of `\theta`, compute the probability that each data point belongs to each of the Gaussian distributions. The Estimation step (E-step) attempts to estimate the missing or latent variables.
- M-step: Given the probabilities computed in the E-step, update the values of `\theta` to maximize the likelihood of the data aggregation. This is the Maximization step (M-step) to best explain the data.
This process is repeated until the values of `\theta` converge to a local maximum of the likelihood function. Once the GMM has been fit, it can be used to make predictions on new data points by computing the weighted average of the PDFs of the Gaussian distributions, using the weights `\pi_k` as the weights.
Data points that exist at the boundary of clusters may simply have similar probabilities of being on either clusters. A mixture model predicts a probability instead of a hard classification such as K-Means clustering.
Advantages: Incorporates uncertainty into the solution.
Disadvantages: Uncertainty may not be desirable for some applications. This method is not as common as the K-Means method for clustering.
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
import numpy as np
X, y = make_blobs(n_samples=800, centers=2,\
n_features=2, random_state=12)
XA, XB, yA, yB = train_test_split(X,y,test_size=0.2,random_state=21)
nB = len(yB)
gmm = GaussianMixture(n_components=2)
gmm.fit(XA)
yP = gmm.predict_proba(XB) # produces probabilities
# Arbitrary labels with unsupervised clustering may need to be reversed
if len(XB[np.round(yP[:,0])!=yB]) > nB/4: yP[:,0] = 1 - yP[:,0]
# Calculate accuracy
print(f'Accuracy = {np.round(100*(nB-np.sum(np.abs(yP[:,0]-yB)))/nB,2)}%')
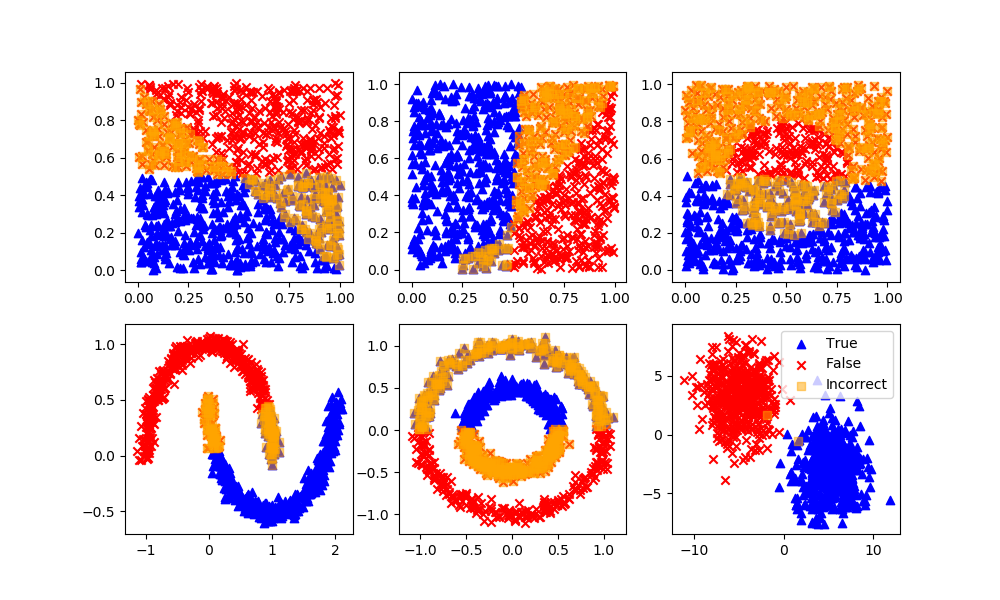
As expected, GMM performs poorly when there is no clustering as seen in the first row of data sets. GMM and other unsupervised learning methods perform better on the second row, as there are gaps between data clusters.
✅ Knowledge Check
1. What is a key distinction between Gaussian Mixture Model (GMM) and K-Means clustering?
- Incorrect. It's the other way around. GMM predicts a probability instead of a hard classification like K-Means clustering.
- Incorrect. GMM assumes that the data is generated by a mixture of multiple Gaussian distributions.
- Correct. Once the GMM has been fit, it can be used to compute the weighted average of the PDFs of the Gaussian distributions.
- Incorrect. The EM algorithm consists of both the E-step (Estimation) and the M-step (Maximization).
2. What does the E-step in the EM algorithm for GMM achieve?
- Incorrect. This is the purpose of the M-step. The E-step estimates the missing or latent variables.
- Correct. The E-step computes the probability for each data point with respect to the Gaussian distributions given the current values of θ.
- Incorrect. This is not the purpose of the E-step. The EM algorithm iterates until θ values converge, but the E-step specifically deals with estimating probabilities.
- Incorrect. GMM predicts probabilities and not hard classifications.
Return to Classification Overview
