Cascade Classifier
Computer vision is how computers automate tasks that mimic human response to visual information. Image features such as points, edges, or patterns are used to identify an object in an image. A cascade classifier uses these visual cues as features to determine if an object is in the image, such as a face.


Image Features
A feature is a piece of information about the content of an image typically about whether a certain region of the image has certain properties. Features can be identified by color, shape, or size of the object.

Features may also be characteristics of the general neighborhood or specific to a small region. Changes from frame to frame in image sequences may also be important features to detect a moving object relative to the surroundings. More broadly a feature is any piece of information which is relevant for solving the computational task related to a certain application. This is the same sense as a feature in machine learning and pattern recognition generally, though image processing has a very sophisticated collection of features. The feature concept is very general and the choice of features in a particular computer vision system may be highly dependent on the specific problem at hand.
- Harris Corner
- Local Binary Pattern (LBP)
- SIFT (Scale Invariant Feature Transform)
- Histogram of Oriented Gradient (HoG)
- SURF (Speeded Up Robust Feature) inspired by SIFT
- FAST (Features from Accelerated Segment Test)
- SUSAN (Smallest Univalue Segment Assimilating Nucleus)
- BASIS (BAsis Sparse-coding Inspired Similarity)
- SYBA (SYthetic BAsis Functions)
Haar-like Features
A Haar-like feature considers adjacent rectangular regions at a specific location in a detection window, sums up the pixel intensities in each region and calculates the difference between these sums. This modified feature set is called 2-rectangle feature. Viola and Jones also defined 3-rectangle features and 4-rectangle features. The detection approach was proposed by Viola and Jones in 2001: Rapid Object Detection using a Boosted Cascade of Simple Features.
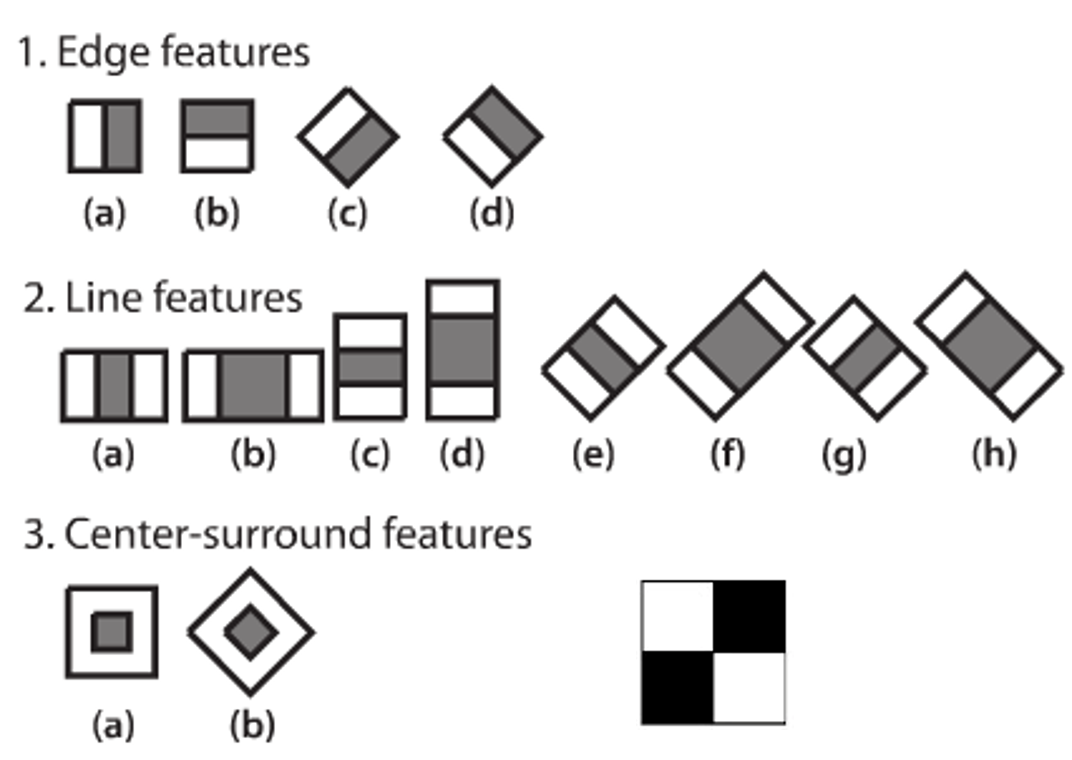
The values indicate certain characteristics of a particular area of the image. Each feature type can indicate the existence (or absence) of certain characteristics in the image, such as edges or changes in texture. For example, a 2-rectangle feature can indicate where the border lies between a dark region and a light region.
Haar Cascade Classifier
Cascading is a particular case of ensemble learning based on the concatenation of several classifiers, using all information collected from the output from a given classifier as additional information for the next classifier in the cascade. Unlike voting or stacking ensembles (multiexpert systems), cascading is a multistage method.
Cascading classifiers are trained with positive sample views of a particular object and arbitrary negative images of the same size. After the classifier is trained it can be applied to a region of an image and detect the object in question. To search for the object in the entire frame, the search window can be moved across the image and check every location for the classifier. This process is most commonly used in image processing for object detection and tracking, primarily facial detection and recognition.
Cascades are usually done through cost-aware AdaBoost. The sensitivity threshold (0.8 in our example) can be adjusted so that there is close to 100% true positives and some false positives. The procedure can then be started again for stage 2, until the desired accuracy/computation time is reached.
After the initial algorithm, it was understood that training the cascade as a whole can be optimized, to achieve a desired true detection rate with minimal complexity. Examples of such algorithms are RCBoost, ECBoost or RCECBoost. In their most basic versions, they can be understood as choosing, at each step, between adding a stage or adding a weak learner to a previous stage, whichever is less costly, until the desired accuracy has been reached. Every stage of the classifier cannot have a detection rate (sensitivity) below the desired rate, so this is a constrained optimization problem. To be precise, the total sensitivity is the product of stage sensitivities.
Activity

Identify the faces in the photo with a Cascade Classifier for Face Detection.

The OpenCV Python package has a pre-built cascade classifier for Face Detection that are stored as an xml file. The decision on face or no face is evaluated in stages that analyze each block of the image. If the stages check fails then the cascade stops and a face is not detected. However, if it continues and passes all of the stages then a face is detected and the bounding box is returned.
import matplotlib.patches as patches
import cv2
import urllib.request
# download image as class.jpg
url = 'http://apmonitor.com/pds/uploads/Main/students_walking.jpg'
urllib.request.urlretrieve(url, 'class.jpg')
# face Cascade Classifier
face=cv2.data.haarcascades+"haarcascade_frontalface_default.xml"
def draw_faces(data, result_list):
for i in range(len(result_list)):
x1, y1, width, height = result_list[i]
x2, y2 = x1 + width, y1 + height
plt.subplot(1, len(result_list), i+1)
plt.axis('off')
plt.imshow(data[y1:y2, x1:x2])
pixels = plt.imread('class.jpg')
faceCascade = cv2.CascadeClassifier(face)
gray = cv2.cvtColor(pixels, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray,scaleFactor=1.1,
minNeighbors=2,\
minSize=(10, 10))
# display only the faces
draw_faces(pixels, faces)
# display identified faces on original image
fig, ax = plt.subplots(); ax.imshow(pixels)
for (x, y, w, h) in faces:
rect = patches.Rectangle((x, y), w, h, lw=2, \
alpha=0.5, edgecolor='r', \
facecolor='none')
ax.add_patch(rect)
plt.show()

The cascade classifier approach is not as accurate as the Multi-task Cascaded Convolutional Neural Network but it is fast for face detection in a video stream. The YOLO algorithm is another alternative for video object detection.

Activity
Run the face detection code that uses a pre-trained cascade classifier. Perform the following tests and note the relative effectiveness of face detection under the following scenarios:
- Look straight ahead at the camera
- Open and close mouth
- Look to the side
- Tilt head side to side
- Move close and far away from the camera
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import cv2
import urllib.request
# Get camera and display video
camera = cv2.VideoCapture(0)
WindowName = 'Cascade Classifier'
cv2.namedWindow(WindowName, cv2.WINDOW_AUTOSIZE)
# Trained cascade classifiers
eye =cv2.data.haarcascades + "haarcascade_eye.xml"
face=cv2.data.haarcascades+"haarcascade_frontalface_default.xml"
# Cascade Classifier
cascade=cv2.CascadeClassifier(face)
start = time.time()
while time.time()-start<=20.0:
# read frame
ret, pixels = camera.read()
# convert to gray scale and identify faces
gray = cv2.cvtColor(pixels, cv2.COLOR_BGR2GRAY)
detect = cascade.detectMultiScale(gray,scaleFactor=1.1,
minNeighbors=3,\
minSize=(30, 30))
# display identified faces on original image
for (x, y, w, h) in detect:
cv2.rectangle(pixels,(x,y),(x+w,y+h),(255,255,0),3)
cv2.imshow(WindowName,pixels)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release camera and video file
camera.release()
cv2.destroyAllWindows()
The face detection can be improved by adjusting the parameters:
- scaleFactor: Parameter specifying how much the image size is reduced at each image scale. A value of 1.05-1.20 is a good range to balance speed (higher numbers) and accuracy (lower numbers). Raising the value to 1.4+ may start to miss a face that is in between scaling sizes.
- minNeighbors: Required neighbors for each candidate rectangle. A higher value means fewer detections but with higher quality. A good range is 3-6.
- minSize and maxSize: Minimum and maximum face size in pixels. A good place to start is [30, 30] for the minSize. The default for maxSize is no upper limit.
minNeighbors=4,\
minSize=(30,30),\
maxSize=(200,200))
Although the Cascade Classifier is fast, the accuracy of this face detection may be low. This is especially the case when the face is anything but directly towards the camera. A more accurate but slower method for face detection is with a Multi-task Cascaded Convolutional Neural Network (MTCNN). MediaPipe provides fast and accurate face detection with a pre-trained Deep Learning model.

import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_face_mesh = mp.solutions.face_mesh
drawing_spec = mp_drawing.DrawingSpec(thickness=1, circle_radius=1)
cap = cv2.VideoCapture(0)
with mp_face_mesh.FaceMesh(max_num_faces=1,refine_landmarks=True,
min_detection_confidence=0.5, min_tracking_confidence=0.5) as face_mesh:
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
# If loading a video, use 'break' instead of 'continue'.
continue
# To improve performance, optionally mark the image as
# not writeable to pass by reference.
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = face_mesh.process(image)
# Draw the face mesh annotations on the image.
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if results.multi_face_landmarks:
for lm in results.multi_face_landmarks:
mp_drawing.draw_landmarks(image=image,landmark_list=lm,
connections=mp_face_mesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_tesselation_style())
mp_drawing.draw_landmarks(image=image,landmark_list=lm,
connections=mp_face_mesh.FACEMESH_CONTOURS,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_contours_style())
mp_drawing.draw_landmarks(image=image,landmark_list=lm,
connections=mp_face_mesh.FACEMESH_IRISES,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_iris_connections_style())
# Flip the image horizontally for a selfie-view display.
cv2.imshow('MediaPipe Face Mesh', cv2.flip(image, 1))
if cv2.waitKey(5) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
✅ Knowledge Check
1. What is the primary purpose of a Haar-like feature for object detection?
- Incorrect. While Haar-like features involve summing up pixel intensities, their primary purpose is not just to sum them up.
- Correct. Haar-like features can indicate where the border lies between a dark region and a light region.
- Incorrect. Haar-like features do not deal with color correction.
- Incorrect. Haar-like features do not reduce image size; they identify specific characteristics in the image.
2. Which of the following describes the cascading process for object detection?
- Incorrect. While scaling might be a part of some image processing tasks, it is not the primary purpose of cascading in object detection.
- Incorrect. Cascading does not primarily focus on enhancing image clarity using filters.
- Correct. Cascading is a multistage method based on the concatenation of several classifiers, using all information collected from the output from a given classifier as additional information for the next classifier.
- Incorrect. Cascading does not involve applying the same classifier repeatedly; it involves multiple classifiers in sequence.
Additional details are available in Deep Learning and Face Detection and Recognition. Other related exercises are Texture Classification, Hand Tracking, Bit and Crack Image Classification, and Soil Classification.
Thanks to DJ Lee, BYU ECE Professor, for the computer vision material and for sharing research and industrial experience with the class.

