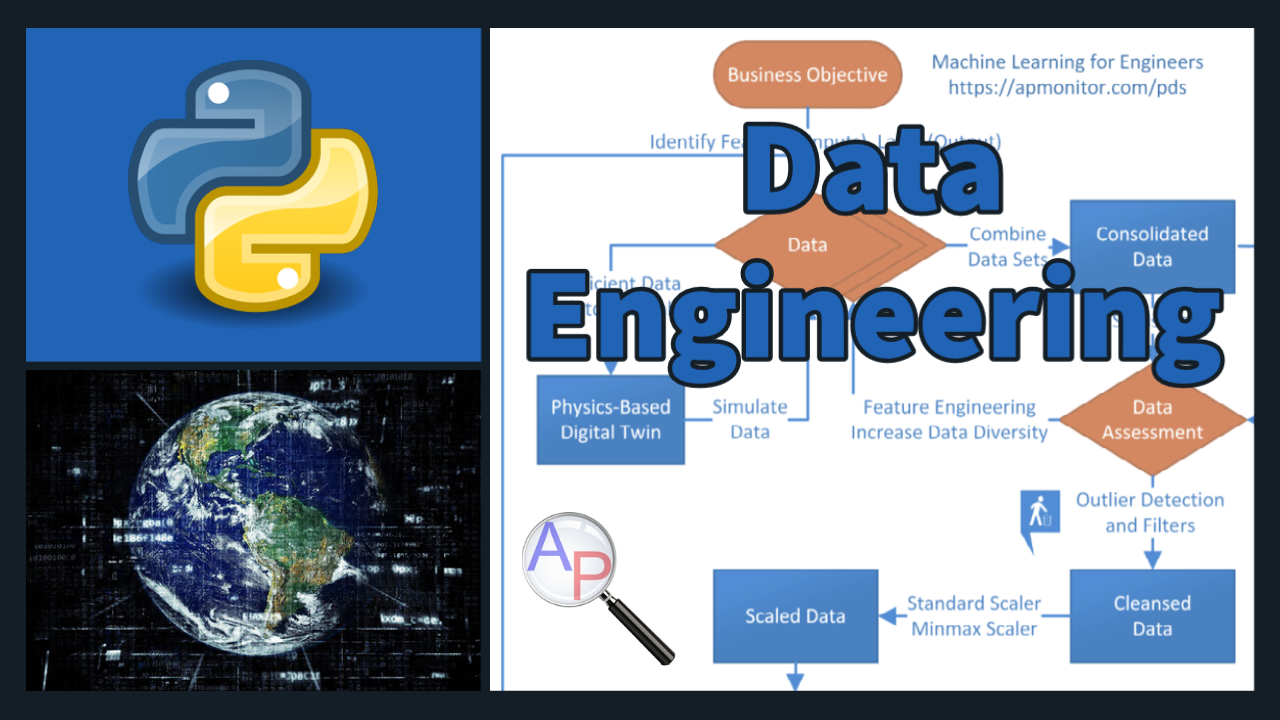
Data Engineering
Data engineering involves storage, consolidation, deployment, visualization, cleansing, scaling, and data division for training, validation, and testing. Data engineers build and maintain the infrastructure to collect, store, and distribute data. Additional information is available in the Data-Driven Engineering Course.

Data Engineering: Part 1
1️⃣ Gathering data is the process of consolidating disparate data (Excel spreadsheet, CSV file, PDF report, database, cloud storage) into a single repository. For time series data, the tables are joined to match features and labels at particular time points.
2️⃣ Statistics provide a compact summary of the data such as number of data sets, mean, standard deviation, and quartile information. A statistical profile of the data shows how much data has been collected and the quality of that data.
3️⃣ Visualization is the graphical representation of data. Visualization is important to have a first look at the data to analyze data diversity, relationships, missing data, bad data, or other factors that may influence decisions to exclude or include an appropriate subset for training.
4️⃣ Data Cleansing is the process of removing bad data that may include outliers, missing entries, failed sensors, or other types of missing or corrupted information.
Data Engineering: Part 2
5️⃣ Feature Engineering is the process of selecting and creating the input descriptors for machine learning. Categorical data is converted to numeric values such as True=1 and False=0. Feature engineering creates indicators from images, words, numbers, or discrete categories. Features are ranked in order of significance. Unimportant features are identified and removed to improve training time, reduce storage cost, and minimize deployment resources.
6️⃣ Imbalanced Data is a problem for classification accuracy because the majority class is favored in the predictions. Oversampling the minority class or undersampling the majority class are two methods to restore balance.
7️⃣ Scaling data (inputs and outputs) to a range of 0 to 1 or -1 to 1 can improve the training process. There are different methods for scaling that are important based on the presence of outliers or statistical properties of the data that may suggest a larger total range so that most of the data is between 0 and 1 or -1 and 1.
8️⃣ Splitting data ensures that there are independent sets for training, testing, and validation. The test set is to evaluate the model fit independently of the training and to improve the hyper-parameters without overfitting on the training. The validation may come with a third split to evaluate the hyperparameter optimization. Cross-validation is an alternative approach to divide the training data into multiple sets that are fit separately and tested on the other set. The parameter consistency is compared between the multiple models. The inputs (features) and outputs (labels) are separated into separate data structures. A loss function such as the squared difference between the predicted label and the measured label is a typical loss (objective) function. A confusion matrix is a graphical representation of misclassification errors.
Data Engineering: Part 3
9️⃣ Deploying machine learning is the process of making the machine learning solution available to produce results for people or computers to access the service remotely. It involves managing data flow to the application for training or prediction. Data flow can be in batches or a continuous stream. The machine learning application may be deployed in many ways such as through an API (Application Programming Interface), a web-interface, an APP for mobile devices, or through a Jupyter Notebook or Python script. If the machine learned model is trained offline, the model is encapsulated and transferred to the hosting target. A scalable deployment means that the computing architecture can handle increased demand such as through a cloud computing host with on-demand scale-up.