Text OCR


Recognizing text information from Human Machine Interface (HMI) screens is an important interface with legacy or proprietary systems to digitize values. These systems might lack open data communication capabilities such as Modbus, MQTT, OPC UA, Websockets, or RESTful / GraphQL / gPRC APIs. OCR recognition of the text on the screen may be important for one or multiple of these reasons:
- Data Accessibility: Legacy and proprietary systems may not provide easy access to the data in digital formats. Extracting text information from HMI screens allows for digitization, making it accessible for further analysis and integration with modern systems.
- Automation: Manual data entry from HMI screens is time-consuming and error-prone. Automating the process of extracting text information enables greater efficiency and accuracy in data collection and processing.
- Integration: Digitized data from HMI screens can be seamlessly integrated into modern software solutions, enabling real-time monitoring, analysis, and reporting, which is vital for decision-making and system optimization.
- Historical Data Preservation: For legacy systems, digitizing HMI screen data is essential for preserving historical records. This helps organizations maintain a comprehensive historical database for compliance, troubleshooting, and maintenance purposes.
- Remote Monitoring: Digitized data allows for remote monitoring of systems, which is particularly important in industries where physical access to the equipment is limited or risky.
Python code recognizes characters on the screen from an image (e.g. PNG) or video frame (e.g. MP4) using the easyocr library. easyocr is a Python library that simplifies Optical Character Recognition (OCR) tasks. Install easyocr using pip:
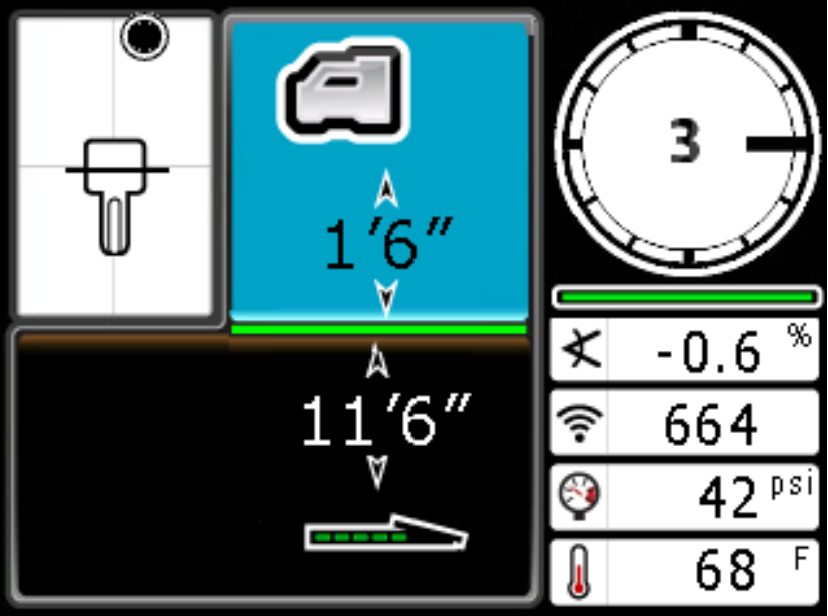
Below is an example code snippet to perform text recognition from an image file from a Falcon F5 locator screen that measures ground depth:
from PIL import Image
import urllib.request
import easyocr
# download image
file = 'falconf5.png'
url = 'http://apmonitor.com/dde/uploads/Main/'+file
urllib.request.urlretrieve(url,file)
# Initialize the PaddleOCR reader
ocr = easyocr.Reader(['en'])
# Read image
img = np.array(Image.open(file))
# Extract values
result = ocr.readtext(img)
for r in result:
print(f'{r[1]} loc: {r[0]} conf: {np.round(r[2],2)}')
The code displays the text, bounding box (in pixels), and the confidence of the OCR:
3 loc: [665, 113], [705, 113], [705, 167], [665, 167] conf: 1.0 1'6" loc: [315, 204], [465, 204], [465, 281], [315, 281] conf: 0.99 A loc: [364, 342], [392, 342], [392, 380], [364, 380] conf: 0.87 X loc: [560, 322], [608, 322], [608, 372], [560, 372] conf: 0.93 -0,6 loc: [650, 324], [768, 324], [768, 378], [650, 378] conf: 0.68 11'6" loc: [290, 383], [483, 383], [483, 457], [290, 457] conf: 1.0 664 loc: [655, 395], [767, 395], [767, 455], [655, 455] conf: 0.99 42 PS loc: [694, 470], [810, 470], [810, 526], [694, 526] conf: 0.58 F loc: [788, 542], [812, 542], [812, 572], [788, 572] conf: 1.0 68 loc: [688, 542], [764, 542], [764, 598], [688, 598] conf: 1.0

Activity: Digitize Values from Video
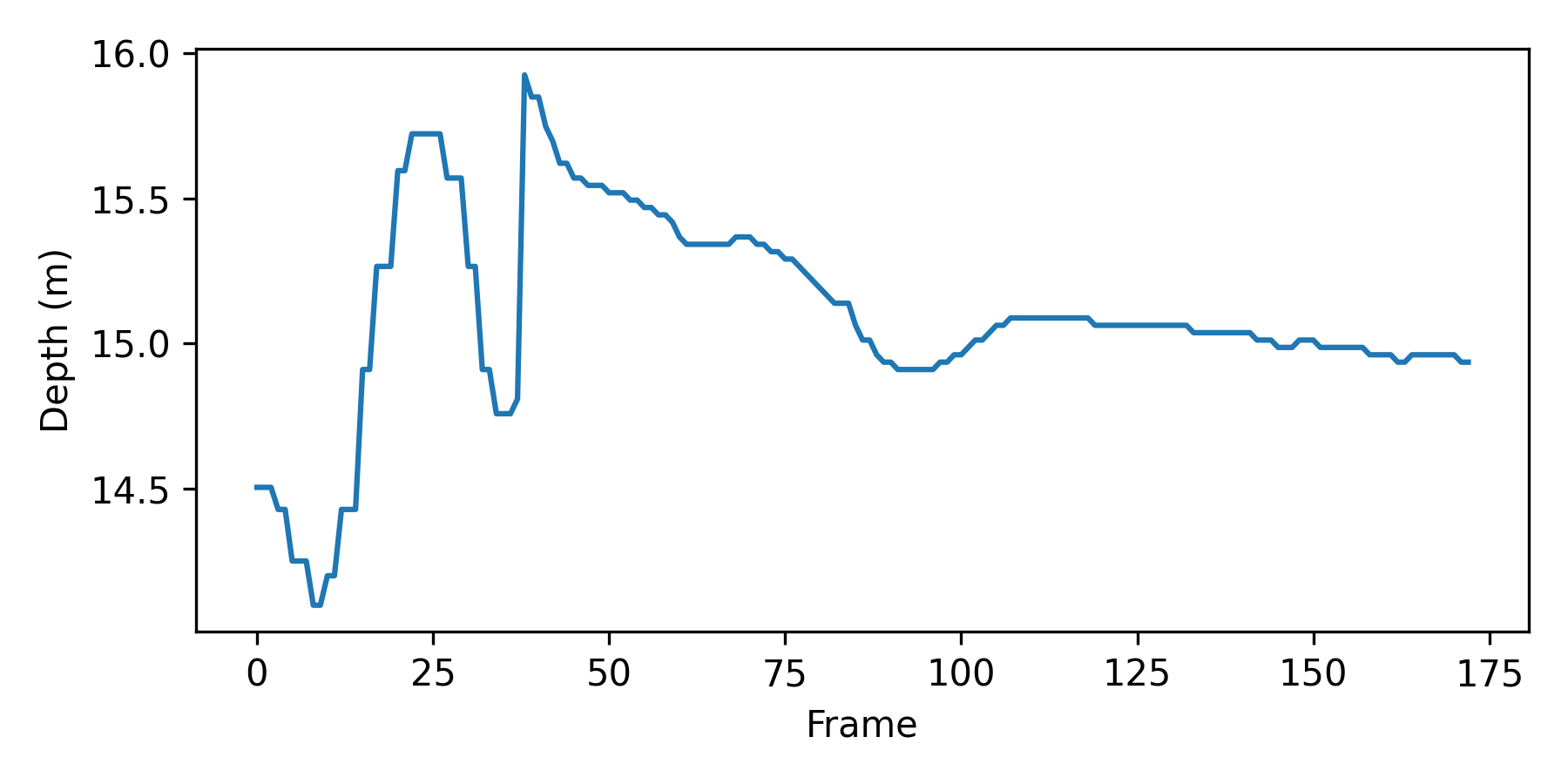
Extend the single image OCR to a video file. Record the series of numbers on the screen in a single CSV (Comma Separated Value) file with a video frame identifier. Create a plot of the depth as the locator repeatedly scans to increase accuracy.
Solution
import urllib.request
import cv2
import easyocr
import matplotlib.pyplot as plt
import pandas as pd
# download video
file = 'dci.mp4'
url = 'http://apmonitor.com/dde/uploads/Main/'+file
urllib.request.urlretrieve(url,file)
# Initialize the reader
ocr = easyocr.Reader(['en'])
# Read video file with OpenCV
cap = cv2.VideoCapture(file)
# results
csv_file = file+'.csv'
# Check if the video file opened
if not cap.isOpened():
print("Error: Could not open video file.")
exit()
# Loop through each frame in the video
ic=0
while True:
print(ic)
ret, frame = cap.read()
# Break the loop when we reach the end of the video
if not ret:
break
# Convert BGR to RGB
img = np.array(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
# Identify text
result = ocr.readtext(img)
# Write header
if ic==0:
fid = open(csv_file,'w')
# write header
for i in range(len(result)):
fid.write(f'data{i},')
fid.write('frame\n')
fid.close()
# write data to file
fid = open(csv_file,'a')
for r in result:
fid.write(f'{r[1]},')
fid.write(f'{ic}\n')
fid.close()
# increment frame counter
ic += 1
# Release the video capture object and close file
cap.release()
# read data
dci = pd.read_csv(csv_file)
# rename columns
dci.columns = ['Read','rm','Depth (ft)','Signal','Frame']
# remove second column
del dci['rm']
# set Frame as index
dci.set_index('Frame',drop=True)
# convert ft' in" to meters
dci['Depth (m)'] = (dci['Depth (ft)'].str.extract("(\d*)'(\d*)\"")
.apply(pd.to_numeric, errors='coerce')
.mul([0.3048, 0.0254]).sum(axis=1)
)
# filter out bad data
dci = dci[dci['Depth (m)']>2]
# create plot of depth
dci['Depth (m)'].plot(figsize=(6,3))
plt.xlabel('Frame'); plt.ylabel('Depth (m)')
plt.tight_layout(); plt.savefig('results.png',dpi=300)
plt.show()