Split Data: Train, Validate, Test
Splitting data ensures that there are independent sets for training, testing, and validation. Data can be divided into sequential blocks where the order is preserved (e.g. time series) or with random selection (shuffle). Cross-validation demonstrates the effect of choosing alternating test sets.



The test set is to evaluate the model fit independently of the training and to improve the hyper-parameters without overfitting on the training. Scikit-learn has a train / test split function with a test_size that is the fraction to reserve for testing.

One Input, Two Outputs
When the data is combined into one set, there are two outputs as train and test sets. The input can be a Pandas dataframe, a Python list, or a Numpy array.
train, test = train_test_split(data, test_size=0.2, shuffle=False)
In this case, 20% of the data at the end is saved for testing. Shuffling the data is not needed because the data sequence is important as a time series.
from sklearn.model_selection import train_test_split
data = pd.read_csv('http://apmonitor.com/pds/uploads/Main/tclab_data6.txt')
data.set_index('Time',inplace=True)
# Split into train and test subsets (20% for test)
train, test = train_test_split(data, test_size=0.2, shuffle=False)
print('Train: ', len(train))
print(train.head())
print('Test: ', len(test))
print(test.head())
Train: 2880
Q1 Q2 T1 T2
Time
0.0 0.0 0.0 16.06 16.00
1.0 0.0 0.0 16.06 15.97
2.0 0.0 0.0 16.06 16.03
3.0 0.0 0.0 16.03 16.00
4.0 0.0 0.0 16.03 15.94
Test: 721
Q1 Q2 T1 T2
Time
2880.0 0.0 0.0 59.25 27.02
2881.0 0.0 0.0 59.22 27.02
2882.0 0.0 0.0 58.99 27.02
2883.0 0.0 0.0 58.93 27.02
2884.0 0.0 0.0 58.93 27.02
Two Inputs, Four Outputs
When the data is already split into features and labels, there are two inputs to the function. The four outputs are X_train, X_test, y_train, and y_test. The inputs can be a Pandas dataframe, a Python list, or a Numpy array.
X, y = make_classification(n_samples=5000, n_features=20, n_informative=15)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, shuffle=True)
print(len(X),len(X_train),len(X_test))
Total Train Test 5000 4000 1000
Train, Validation, Test
The validation may come with a third split to evaluate the hyperparameter optimization. Validation data is a split of the training set to use during the fitting. It is training data that is reserved for evaluating the loss function to detect overfitting.
Cross-Validation
Cross-validation is an alternative approach to divide the training data into multiple sets that are fit separately and tested on the other set.
KFold(n_splits=5,shuffle=True)
The parameter consistency is compared between the multiple models. This example shows how to perform a K-fold cross-validation with the data split 5 ways.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.datasets import make_classification
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# define dataset
X, y = make_classification(n_samples=5000, n_features=20, n_informative=15)
# Set up K-fold cross validation
kf = KFold(n_splits=5,shuffle=True)
# Initialize model
dtc = DecisionTreeClassifier()
# Array to store accuracy scores
scores = np.zeros(5)
# Initialize plot
plt.figure(figsize=(12,2))
for i,(train_index, test_index) in enumerate(kf.split(X)):
Xtrain, Xtest = X[train_index], X[test_index]
ytrain, ytest = y[train_index], y[test_index]
dtc.fit(Xtrain,ytrain)
yp = dtc.predict(Xtest)
acc = accuracy_score(ytest,yp)
scores[i] = acc
plt.subplot(1,5,i+1)
cm = confusion_matrix(yp,ytest)
sns.heatmap(cm,annot=True)
plt.show()
print('Accuracy: %.2f%%' %(np.mean(scores*100)))
A confusion matrix is a graphical representation of misclassification errors. The accuracy of the classifier over the 5 cases is 81%.
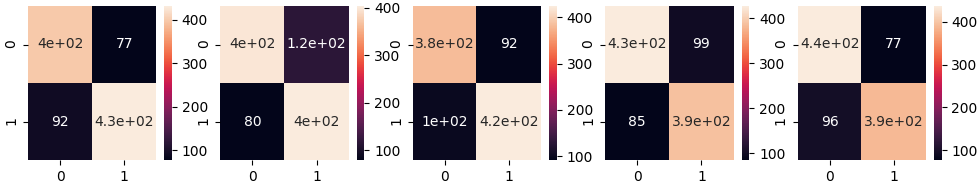

✅ Knowledge Check
1. What is the primary purpose of splitting the data into train and test sets?
- Incorrect. Splitting data into training and test sets ensures that the model is tested on independent data it hasn't seen before. This helps to evaluate its real-world performance.
- Correct. The test set is used to evaluate the model fit independently of the training and to improve the hyper-parameters without overfitting on the training.
- Incorrect. While training on smaller datasets can be faster, the primary purpose of splitting data is to ensure independent evaluation of the model's performance.
- Incorrect. While a test set can potentially expose underfitting, its primary purpose is to ensure the model's ability to generalize to new, unseen data.
2. In the given Python code for splitting data, why was the shuffle parameter set to False?
- Incorrect. The primary purpose of the shuffle parameter isn't about speed. It determines whether to randomize the data before splitting.
- Incorrect. Setting shuffle to False ensures the last 20% of the data is used for testing, not the first.
- Correct. In time series data, the sequence of data points is crucial. Shuffling could disrupt the chronological order.
- Incorrect. The default value for shuffle in train_test_split is actually True, meaning the data is randomized by default before splitting.
