Machine Learning Exam
This exam covers content from data engineering to machine learning models and provides engineers with the tools and knowledge to apply machine learning techniques with classification, regression, and clustering.

In the Data Engineering section of the course, students begin with a foundational understanding of the significance of data in machine learning. They:
- Gather Data: Learn the importance of collecting relevant, high-quality data from various sources, understanding that the quality of data significantly impacts the outcome of machine learning models.
- Statistics: Dive into statistical methods to summarize and interpret the gathered data, providing insights into data distribution, variance, and other key metrics.
- Visualize: Explore various data visualization techniques to gain a deeper understanding of the data trends and patterns, which aids in initial analysis.
- Cleanse: Understand the need to preprocess and clean data, removing anomalies, outliers, and handling missing values to ensure accurate model training.
- Features: Delve into feature engineering where raw data is transformed or new variables are created to improve model efficacy.
- Balance: Learn about the challenges of imbalanced datasets and techniques to overcome such issues, ensuring that the model is not biased.
- Scale: Understand the importance of normalizing or standardizing data, especially when features have different scales.
- Split: Grasp the importance of dividing data into training, validation, and test sets to ensure models are generalizable and avoid overfitting.
- Deploy: Finally, explore how to deploy machine learning models into production, understanding the challenges and best practices associated with real-world deployments.
In the Classification area, the course shifts focus to categorizing data. After a broad overview, students explore:
- Hyperparameters: Techniques to fine-tune and optimize model parameters.
- Cybersecurity: The implications of machine learning in cybersecurity and how models can be secured against threats.
- Supervised Learning: Delving deep into algorithms such as AdaBoost, Decision Tree, k-Nearest Neighbors, Logistic Regression, Naïve Bayes, Neural Network Classifier, Random Forest, Stochastic Gradient Descent, Support Vector Classifier, and the XGBoost Classifier.
- Unsupervised Learning: Here, the emphasis is on models that work without labeled data, covering the Gaussian Mixture Model, K-Means Clustering, and Spectral Clustering.
The Regression area covers predictions of continuous values. After an overview, the course moves into specific regression algorithms such as:
- Linear Regression, k-Nearest Neighbors for regression, Support Vector Regressor, Gaussian Processes, Neural Network Regressor, and XGBoost Regressor.
Part I: Classification, Regression, and Clustering
- Classification is a type of supervised learning where the goal is to categorize data into predefined classes or labels. In classification, the output variable is categorical, like "defect" or "no defect", "fraudulent" or "valid".
- Regression: Regression, also a type of supervised learning, is used when the output variable is a real or continuous value. Examples include predicting house prices, temperature, sales amounts, or any other continuous quantity.
- Clustering: Unlike supervised methods, clustering falls under unsupervised learning. It involves grouping data points based on their similarity without having pre-defined labels for the groups. The objective is to segregate datasets into clusters where data points in the same cluster are more similar to each other than those in other clusters.
In this section, you'll encounter 10 scenarios. For each, determine whether the described method is an example of Classification, Regression, or Clustering. Choose the appropriate category for each question.
1. In a chemical plant, you want to predict the yield of a reaction based on temperature, pressure, and catalyst concentration. What type of machine learning is this?
- Incorrect. Classification is used to categorize data into predefined labels.
- Incorrect. Clustering groups data based on similarities but does not predict specific outcomes.
- Correct. Regression predicts a continuous value based on input features.
2. You are trying to group customers of an engineering software product based on their usage patterns. No customer labels (categories) are collected, but features from usage are available. Which machine learning method is this?
- Incorrect. Classification uses labeled data to assign new data to predefined categories.
- Correct. Clustering groups data based on similarities without predefined labels.
- Incorrect. Regression predicts a continuous value, not group data.
3. A manufacturing firm wants to predict the average number (continuous value) of defects in their products based on various parameters like machine speed, temperature, and material quality. What type of machine learning method is this?
- Correct. Regression predicts a continuous value based on input features.
- Incorrect. Clustering does not predict specific values.
- Incorrect. Classification categorizes data but does not predict continuous values.
4. Given a dataset with a mix of genuine and fraudulent transactions, you want to categorize them. Which type of machine learning is this?
- Correct. Classification categorizes data into predefined labels.
- Incorrect. Clustering would group data based on similarities but won't specifically categorize as genuine or fraudulent.
- Incorrect. Regression predicts continuous values, not categorizes data.
5. An engineering firm collects data from sensors across a bridge. They want to group the data to understand different patterns of vibration and strain without any output labels. What type of machine learning is this?
- Incorrect. Classification uses predefined labels, not for discovering patterns without labels.
- Correct. Clustering groups data based on similarities without predefined labels.
- Incorrect. Regression predicts continuous values, not for discovering patterns.
6. In a water treatment plant, engineers want to predict the level of contaminants in the outlet based on the inlet water quality and operational parameters. Which machine learning method is this?
- Correct. Regression predicts a continuous value based on input features.
- Incorrect. Clustering groups data based on similarities without aiming for specific predictions.
- Incorrect. Classification would categorize data but doesn't predict specific continuous values.
7. Engineers at a wind farm want to categorize wind turbines based on their performance metrics without any information on which gear boxes are defective. What type of machine learning method is this?
- Correct. Clustering groups data based on similarities without predefined labels.
- Incorrect. Regression predicts continuous values, not for discovering patterns or categorizing.
- Incorrect. Classification uses predefined labels, which isn't mentioned in this scenario.
8. In a semiconductor manufacturing facility, the aim is to predict the electrical resistance of a chip based on various manufacturing parameters. Which machine learning method is suitable?
- Incorrect. Classification categorizes data but doesn't predict specific continuous values.
- Correct. Regression predicts a continuous value based on input parameters.
- Incorrect. Clustering aims to group data based on similarities, not to make specific predictions.
9. A factory collects vibration data from various machines and wants to detect machines that operate in a similar manner. Which method of machine learning applies?
- Correct. Clustering groups data based on similarities without the use of predefined labels.
- Incorrect. Classification uses predefined labels to categorize data.
- Incorrect. Regression is for predicting continuous values.
10. Engineers aim to categorize different alloys based on their stress-strain curves from a tensile test. The type of alloy is specified in the training data. What type of machine learning is this?
- Incorrect. Regression predicts continuous outcomes, not categorization.
- Correct. Classification categorizes data into predefined labels.
- Incorrect. Clustering would group data based on similarities without specific categorization.
Part II: Regression
Regression is a cornerstone technique in machine learning that aims to model and analyze the relationships between variables. This section delves into various regression methods, ranging from the fundamental linear approach to more complex strategies like XGBoost and neural network regressors.
1. Which of the following regression techniques is primarily based on distance measurement to predict the output value?
- Incorrect. Support Vector Regressor is primarily based on finding the hyperplane which best divides a dataset into classes.
- Incorrect. Neural networks use layers of nodes to process input data and make predictions.
- Correct. k-Nearest Neighbors predict the output value based on the average of the k most similar instances.
- Incorrect. Gaussian Processes are based on probability distributions over possible functions.
2. Which regression model uses boosting to improve its performance?
- Incorrect. Neural networks do not inherently use boosting; they utilize layered structures.
- Incorrect. k-Nearest Neighbors is a lazy learner and doesn't use boosting.
- Incorrect. Support Vector Regressor doesn't use boosting; it uses support vectors for predictions.
- Correct. XGBoost stands for eXtreme Gradient Boosting and inherently uses boosting to enhance its performance.
3. Which regression technique primarily focuses on minimizing the margin error between the actual and predicted values?
- Correct. Support Vector Regressor aims to find a hyperplane with a maximum margin of error, minimizing the error between actual and predicted values.
- Incorrect. Gaussian Processes focus on distributions over possible functions.
- Incorrect. Neural networks use layered nodes and weights to make predictions.
- Incorrect. Linear Regression tries to fit a line that best captures the relationship between input and output.
4. In which regression method is the underlying assumption that the relationship between inputs and output can be represented by a linear equation?
- Correct. Linear Regression assumes a linear relationship between the input variables and the output.
- Incorrect. XGBoost doesn't assume a linear relationship; it builds decision trees.
- Incorrect. Neural networks can capture non-linear relationships and don't strictly assume linearity.
- Incorrect. k-Nearest Neighbors is based on distance and doesn't assume a linear relationship.
5. Which of the following regression techniques is non-parametric?
- Incorrect. Linear Regression is parametric as it assumes a specific form for the underlying function.
- Incorrect. Neural networks, while flexible, do have parameters (weights and biases).
- Correct. Gaussian Processes are non-parametric as they make no fixed assumptions on the functional form of the data.
- Incorrect. Support Vector Regressor, while flexible, operates based on support vectors and margins.
Part III: Classification
This is a series of questions centered on classification techniques, both supervised and unsupervised. The questions probe into algorithm-specific attributes, such as feature selection, assumptions of independence, and the role of ensemble methods.
1. Which classification algorithm inherently performs feature selection by considering subsets of features at each split?
- Incorrect. AdaBoost is an ensemble method that focuses on re-weighting instances, not feature selection.
- Incorrect. Neural networks use all the provided features unless feature selection is done separately.
- Correct. Random Forest randomly selects a subset of features for making each split, leading to feature selection.
- Incorrect. Logistic Regression doesn't perform inherent feature selection; it uses all provided features.
2. Which classifier assumes that the features are conditionally independent given the class?
- Correct. Naïve Bayes assumes conditional independence between features for a given class.
- Incorrect. Decision Trees split based on feature values but don't assume conditional independence.
- Incorrect. k-NN is a lazy learner and doesn't make assumptions about feature independence.
- Incorrect. Support Vector Classifier finds hyperplanes in the feature space and doesn't assume feature independence.
3. Which of the following is an unsupervised learning method focused on grouping data into clusters?
- Incorrect. AdaBoost is a supervised ensemble learning method.
- Incorrect. Logistic Regression is a supervised classification method.
- Correct. Spectral Clustering is an unsupervised learning method aimed at grouping data into clusters.
- Incorrect. Neural Network Classifier is a supervised learning method.
4. Which classification algorithm utilizes a loss function that encourages solutions with large margins?
- Incorrect. Random Forest is an ensemble of decision trees and doesn't focus on margins.
- Correct. Support Vector Classifier works on finding hyperplanes that classify data with the largest possible margin.
- Incorrect. Neural networks classify based on learned weights and activations but don't focus on margins.
- Incorrect. Stochastic Gradient Descent is an optimization algorithm and the focus on margins depends on the chosen loss function.
5. In which of the following classification algorithms do ensemble techniques play a role?
- Correct. XGBoost stands for eXtreme Gradient Boosting and uses ensemble techniques.
- Incorrect. k-Nearest Neighbors is a lazy learner that predicts based on the majority class of its neighbors.
- Incorrect. Logistic Regression predicts probabilities based on the logistic function and doesn't use ensemble techniques.
- Incorrect. Gaussian Mixture Model is an unsupervised clustering algorithm that doesn't utilize ensemble techniques.
6. What is the number of Type-II errors (False negatives) from this confusion matrix?
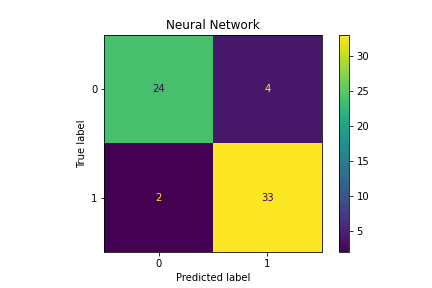
- Incorrect. The predicted label is 0 and the true label is 0. These 24 are correctly classified.
- Incorrect. The predicted label is 1 and the true label is 0. These 4 are incorrectly classified and are False-Positives (Type-I errors).
- Correct. The predicted label is 0 and the true label is 1. These 2 are incorrectly classified and are False-Negatives.
- Incorrect. The predicted label is 1 and the true label is 1. These 33 are correctly classified.
7. What is the accuracy of the k-Nearest Neighbors classifier on the Test Set with k=2 for this example with cats and dogs?
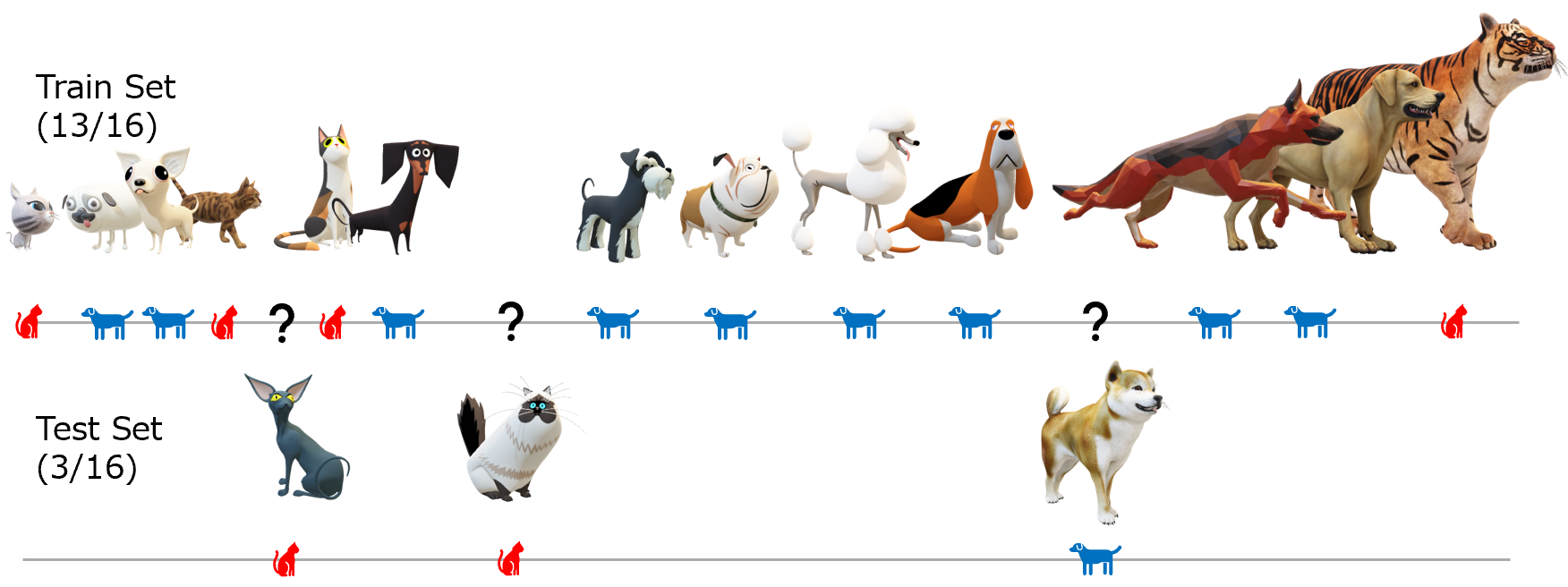
The accuracy is defined as:
Accuracy = (Correct Classifications in Test Set)
/(Total Number of Test Samples) x 100%
- Incorrect. The accuracy is 2/3 or 66.7%.
- Incorrect. One of the cats in the test set is incorrectly classified as a dog.
- Incorrect. A cat and a dog are classified correctly.
- Correct. The accuracy is 2/3 or 66.7%.
Part IV: Classification and Regression Case-Study

This case study explores additive manufacturing, a process where materials such as polymer, ceramic, or metallic powder are precisely layered based on computer-aided designs to create three-dimensional products. It facilitates rapid prototype development and is efficient for products requiring customization or for those produced in low volumes. The dataset focuses on 3D printing conditions for two materials: Polylactic Acid (PLA) and Acrylonitrile Butadiene Styrene (ABS), both with unique properties and temperature requirements. The objectives are:
- Data Visualization and Cleansing: Statistically characterize the data, identify and remove outliers, and determine factors highly correlated to the material used and the tension strength.
- Classification: Create models to classify the type of filament material used in printing, either PLA or ABS.
- Regression: Predict the tension strength based on various machine settings. Develop regression models to analyze performance. Address concerns about the relative strength of PLA to ABS by comparing the predicted strength for the test points.
Create a 2-page summary report detailing the results, correlating variables, classifier prediction abilities, and the relative strengths of the materials. The objective is to demonstrate analytical and data-processing skills and deepen understanding of additive manufacturing in the context of materials science and engineering.
