RAG and LLM Integration


Applications of Retrieval-Augmented Generation (RAG) and Large Language Models (LLMs) give context-aware solutions for complex Natural Language Processing (NLP) tasks. Natural language processing (NLP) is a machine learning technology that gives computers the ability to interpret, manipulate, and interact with human language.
Combining RAG and LLMs enables personalized, multilingual, and context-aware systems. The objective of this tutorial is to implement RAG for user-specific data handling, develop multilingual RAG systems, use LLMs for content generation, and integrate LLMs in code development.
Retrieval-Augmented Generation (RAG)

RAG Similarity Search is a tutorial on ChromaDB to create a vector store from the Gekko Optimization Suite LLM training data train.jsonl file to retrieve questions and answers that are similar to a query. The tutorial is a guide to install necessary libraries, import modules, and prepare the Gekko training data to build the vector store. It emphasizes the significance of similarity search with k-Nearest Neighbors, with a vector store either in memory or on a local drive. It includes an exercise where participants create question-answer pairs on a topic of interest, construct a vector database, and perform similarity searches using ChromaDB.
import chromadb
# read Gekko LLM training data
url='https://raw.githubusercontent.com'
path='/BYU-PRISM/GEKKO/master/docs/llm/train.jsonl'
qa = pd.read_json(url+path,lines=True)
documents = []
metadatas = []
ids = []
for i in range(len(qa)):
s = f"### Question: {qa['question'].iloc[i]} ### Answer: {qa['answer'].iloc[i]}"
documents.append(s)
metadatas.append({'qid':f'qid_{i}'})
ids.append(str(i))
# in memory
cc = chromadb.Client()
collection = cc.create_collection(name='mydb')
collection.add(
documents=documents,
metadatas=metadatas,
ids=ids
)
results = collection.query(
query_texts=['What are you trained to do?'],
n_results=5,include=['distances','documents'])
print(results)
LLM with Ollama Python Library

LLM with Ollama Python Library is a tutorial on Large Language Models (LLMs) with Python with the ollama library for chatbot and text generation. It covers the installation of the ollama server and ollama python package and uses different LLM models like mistral, gemma, phi, and mixtral that vary in parameter size and computational requirements.
prompt = 'What are you trained to do?'
stream = ollama.chat(model='mistral',
messages=[{'role': 'user', 'content': prompt}],
stream=True,)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
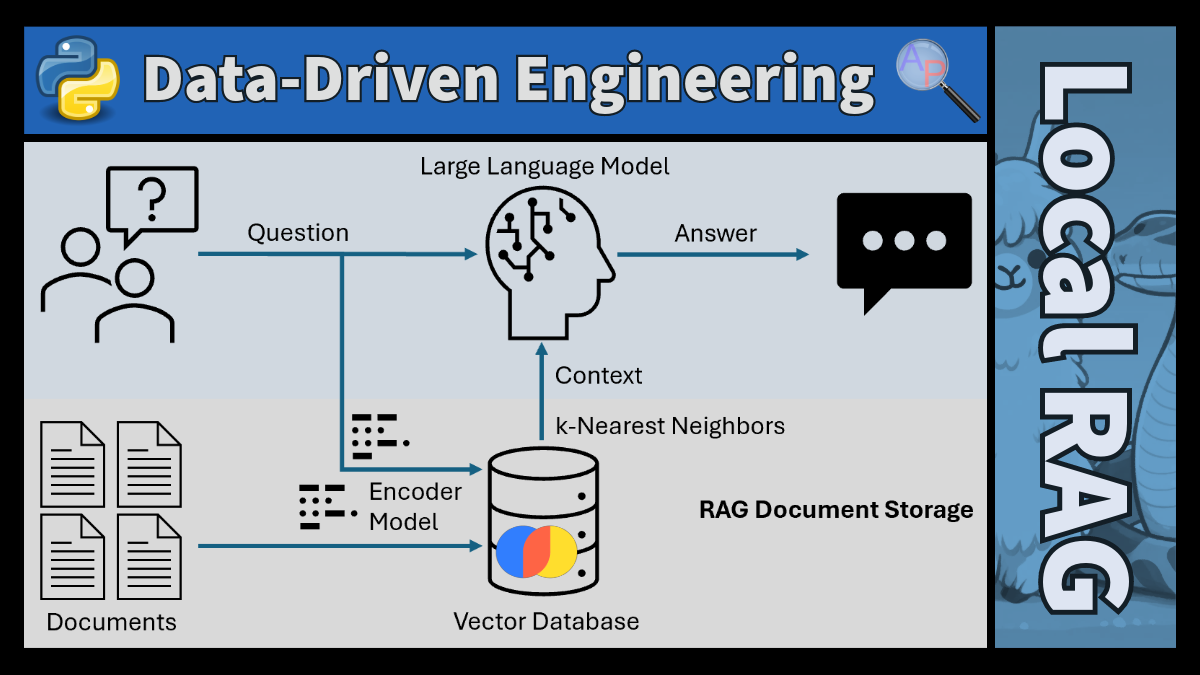
RAG and LLM Integration
Combining Retrieval-Augmented Generation (RAG) with Large Language Models (LLMs) leads to context-aware systems. RAG optimizes the output of a large language model by referencing an external authoritative knowledge base outside of initial training data sources. These external references generate a response to provide more accurate, contextually relevant, and up-to-date information. In this architecture, the LLM is the reasoning engine while the RAG context provides relevant data. This is different than fine-tuning where the LLM parameters are augmented based on a specific knowledge database.
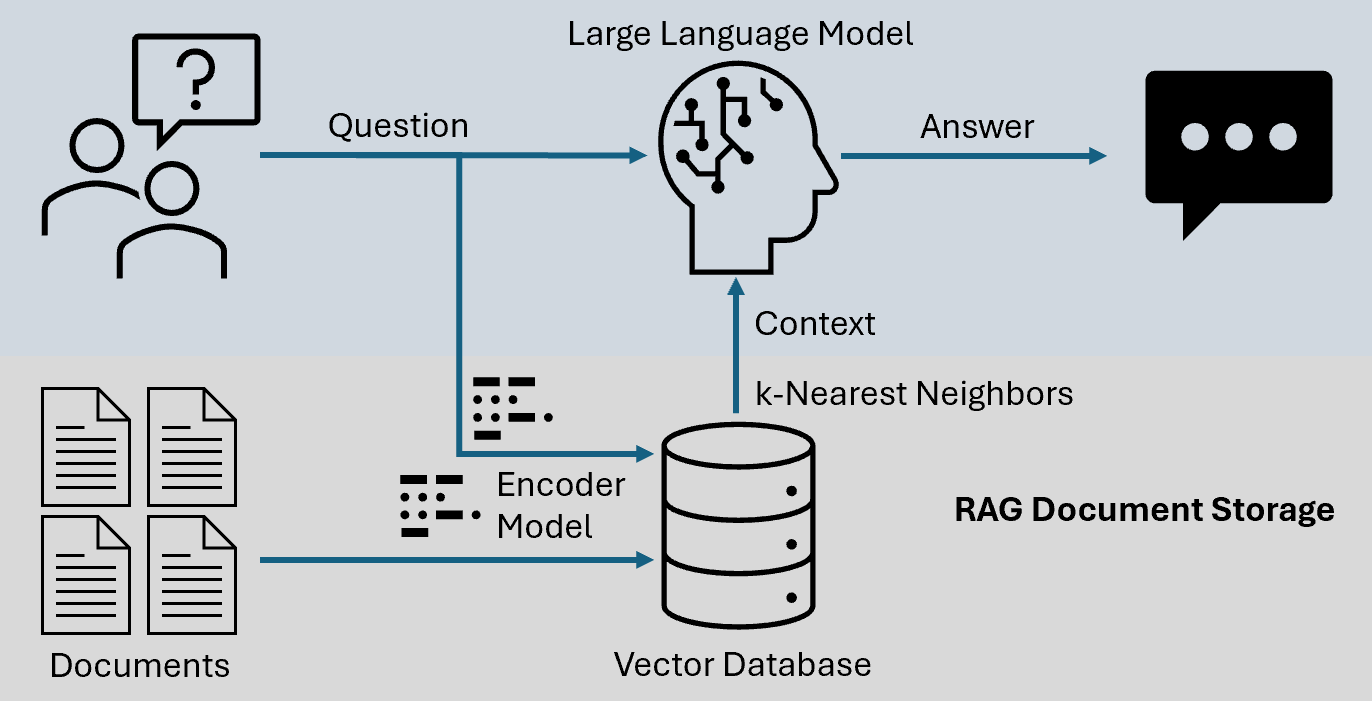
The synergy of RAG enhances the LLM ability to generate responses that are not only coherent and contextually appropriate but also enriched with the latest information and data, making it valuable for applications that require higher levels of accuracy and specificity, such as customer support, research assistance, and specialized chatbots. This combines the depth and dynamic nature of external data with the intuitive understanding and response generation of LLMs for more intelligent and responsive AI systems.
RAG with LLM (Local)
The Local RAG with LLM downloads the train.jsonl file to provide context-aware information about Gekko questions using the mistral model. The processing of the LLM may take substantial time (minutes) if there are insufficient GPU resources available to process the request.
import pandas as pd
import chromadb
# Loading and preparing the ChromaDB with data
def setup_chromadb():
# read Gekko LLM training data
url='https://raw.githubusercontent.com'
path='/BYU-PRISM/GEKKO/master/docs/llm/train.jsonl'
qa = pd.read_json(url+path,lines=True)
documents = []
metadatas = []
ids = []
for i in range(len(qa)):
s = f"### Question: {qa['question'].iloc[i]} ### Answer: {qa['answer'].iloc[i]}"
documents.append(s)
metadatas.append({'qid': f'qid_{i}'})
ids.append(str(i))
cc = chromadb.Client()
cdb = cc.create_collection(name='gekko')
cdb.add(documents=documents, metadatas=metadatas, ids=ids)
return cdb
# Ollama LLM function
def ollama_llm(question, context):
formatted_prompt = f"Question: {question}\n\nContext: {context}"
response = ollama.chat(model='mistral', messages=[{'role': 'user', 'content': formatted_prompt}])
return response['message']['content']
# Define the RAG chain
def rag_chain(question, cdb):
context = cdb.query(query_texts=[question],
n_results=5, include=['documents'])
formatted_context = "\n\n".join(x for x in context['documents'][0])
formatted_context += "\n\nYou are a professional and technical assistant trained to answer questions about Gekko, which is a high-performance Python package for optimization, simulation, machine learning, data-science, model predictive control, and parameter estimation. In addition, you can also help with answering questions about programming in Python, particularly in relation to the aforementioned topics. Your primary goal is to assist users in finding solutions and gaining knowledge in these areas."
result = ollama_llm(question, formatted_context)
return result
# Setup ChromaDB
cdb = setup_chromadb()
# Create prompt for Local RAG LLM
question = 'What are you trained to do?'
out = rag_chain(question, cdb)
print(out)
Answer: I am a professional and technical assistant specifically trained to answer questions related to Gekko, a high-performance Python package for optimization, simulation, machine learning, data-science, model predictive control, and parameter estimation. I can also help with programming-related queries in Python, particularly within the context of these topics. My primary goal is to assist users in finding accurate information and expanding their knowledge in these areas. I have been trained on hundreds of examples. Let me know if you have any specific questions or if there's something I can help with!
Cloud Service RAG with LLM
The same RAG with LLM program is available in the Gekko support module. The question is sent to a server that has sufficient GPU resources to run the mixtral model with the RAG similarity search to provide question context.
from gekko import support
assistant = support.agent()
assistant.ask('How do I install gekko?')
Question: How do I install gekko?
Answer:
To install Gekko, you can use pip, which is a package manager for Python. Here are the steps to install Gekko:
1. Open your command prompt or terminal window.
2. Type the following command and press enter:
If you encounter any issues during installation, try updating pip with the following command:
Then, run the pip install gekko command again.
Once Gekko is installed, you can import it in your Python script and start using its features for optimization, simulation, machine learning, data-science, model predictive control, and parameter estimation. If you need further assistance or documentation, please refer to the Gekko documentation on ReadtheDocs or the APMonitor website.
If you have any issues with the installation process or if you encounter any errors while using Gekko, feel free to ask for help by posting a question on StackOverflow with the tag 'gekko' or by opening a new issue on GitHub for the Gekko package.
Gekko AI Assistant
A dynamic platform hosts the Gekko AI Assistant as a support tool to transform the user experience beyond the Python environment. It is a chat web interface to harnesses the power of Large Language Models (LLMs) and cloud-based resources to deliver an interactive, intelligent, and responsive service. It is accessible on mobile or desktop environments for those seeking quick information or support with complex problem-solving.

Activity: RAG and LLM Chatbot
Use a JSONL template to generate at least 10 questions and answers based on a topic of your interest and save the file as mydb.jsonl.
{"question":"","answer":""}
{"question":"","answer":""}
{"question":"","answer":""}
{"question":"","answer":""}
{"question":"","answer":""}
{"question":"","answer":""}
{"question":"","answer":""}
{"question":"","answer":""}
{"question":"","answer":""}
Adapt the RAG with LLM code above to create a custom chatbot on the topic of your interest. Choose a topic where you are a domain expert and generate at least 10 question-answer pairs. Once done, you'll build a vector database with these pairs and perform a similarity search using ChromaDB that can be used to enhance the context of the LLM.
AI Triathlon Assistant

An AI Triathlon Assistant uses a Retrieval-Augmented Generation (RAG) with an LLM. Here's an overview of the process:
1. Data Collection and Curation: Gather an up-to-date dataset related to triathlons. This dataset should include information on training regimes, equipment, race strategies, nutrition, and rules for various triathlon formats (like sprint, Olympic, and Ironman distances).
2. Build the Retrieval System: Develop or integrate a retrieval system that can efficiently search through the triathlon dataset. This system should be capable of understanding the context of a query and retrieving the most relevant information with ChromaDB.
3. Integrate the RAG Architecture: Combine the language model with the retrieval system. The RAG setup enables the model to first retrieve relevant information based on the user query and then generate a response using both the retrieved information and pre-trained knowledge.
import pandas as pd
import chromadb
# Loading and preparing the ChromaDB with data
def setup_chromadb():
try:
qa = pd.read_json('mydb.jsonl',lines=True)
except:
# file not found, create file
fid = open('mydb.jsonl','w')
fid.write('''{"question":"What are the three disciplines of a triathlon?","answer":"The three disciplines of a triathlon are swimming, cycling, and running."}
{"question":"What is the standard distance for an Olympic triathlon?","answer":"An Olympic triathlon consists of a 1.5 km swim, a 40 km bike ride, and a 10 km run."}
{"question":"How do transition areas work in a triathlon?","answer":"Transition areas are used to switch between disciplines. The first transition (T1) is from swimming to cycling, and the second transition (T2) is from cycling to running."}
{"question":"What is an Ironman Triathlon?","answer":"An Ironman Triathlon is a long-distance triathlon race consisting of a 3.86 km swim, 180.25 km bike ride, and a marathon 42.20 km run."}
{"question":"Can relay teams participate in triathlons?","answer":"Yes, relay teams can participate in triathlons, with each team member completing one segment of the race."}
{"question":"What is the purpose of a wetsuit in triathlon swimming?","answer":"A wetsuit provides buoyancy, warmth, and speed enhancement during the swimming portion of a triathlon."}
{"question":"How do triathletes train for a triathlon?","answer":"Triathletes train by developing endurance, strength, and technique in swimming, cycling, and running, often with a balanced training schedule."}
{"question":"What are drafting rules in triathlon cycling?","answer":"Drafting rules in triathlon cycling vary by race. Some races allow drafting, while others, like Ironman races, prohibit it to ensure fairness and safety."}
{"question":"What nutrition is recommended for triathletes during a race?","answer":"Triathletes are recommended to have a balance of carbohydrates, electrolytes, and fluids during the race to maintain energy and hydration levels."}
{"question":"Are there age-group categories in triathlons?","answer":"Yes, most triathlons have age-group categories, allowing athletes of similar ages to compete against each other."}''')
fid.close()
qa = pd.read_json('mydb.jsonl',lines=True)
documents = []
metadatas = []
ids = []
for i in range(len(qa)):
s = f"### Question: {qa['question'].iloc[i]} ### Answer: {qa['answer'].iloc[i]}"
documents.append(s)
metadatas.append({'qid': f'qid_{i}'})
ids.append(str(i))
cc = chromadb.Client()
cdb = cc.create_collection(name='triathlon')
cdb.add(documents=documents, metadatas=metadatas, ids=ids)
return cdb
# Ollama LLM function
def ollama_llm(question, context):
formatted_prompt = f"Question: {question}\n\nContext: {context}"
response = ollama.chat(model='mixtral', messages=[{'role': 'user', 'content': formatted_prompt}])
return response['message']['content']
# Define the RAG chain
def rag_chain(question, cdb):
context = cdb.query(query_texts=[question],
n_results=5, include=['documents'])
formatted_context = "\n\n".join(x for x in context['documents'][0])
formatted_context += "\n\nI am an AI Triathlon assistant with detailed knowledge about the three disciplines involved in a triathlon (swimming, cycling, and running), the standard distances for different types of triathlon races such as the Olympic triathlon and Ironman Triathlon, and specifics about the transitions between each segment of the race. I am well-versed in the rules and strategies that pertain to each aspect of a triathlon. This includes understanding the significance of equipment such as wetsuits in the swimming segment, the rules around drafting in the cycling portion, and the specific nutritional requirements for triathletes during a race. Additionally, I have information regarding the training methods and schedules used by triathletes to prepare for races, the role of relay teams in triathlons, and the categorization of competitors in different age groups. This information allows me to answer questions related to triathlon races, training, rules, equipment, and strategies effectively and accurately. My responses are informed by a comprehensive set of data and details about triathlons, making me a valuable resource for anyone seeking knowledge in this area."
result = ollama_llm(question, formatted_context)
return result
# Setup ChromaDB
cdb = setup_chromadb()
# Create prompt for Local RAG LLM
question = 'What is the total distance of an Ironman?'
out = rag_chain(question, cdb)
print(out)
4. Testing and Feedback Loop: Before deployment, test the system with real users, including both triathlon enthusiasts and professionals. Collect feedback on the accuracy, relevance, and helpfulness of the responses generated by the AI.