Dynamic Control Objectives
The dynamic control objective function is a mathematical statement that is minimized or maximized to find a best solution among all possible feasible solutions for a controller. The form of this objective function is critical to give desirable solutions for driving a system to a desirable state or along a desired trajectory. Common objective statements relate to economic, safety, operability, environmental, or related objectives.

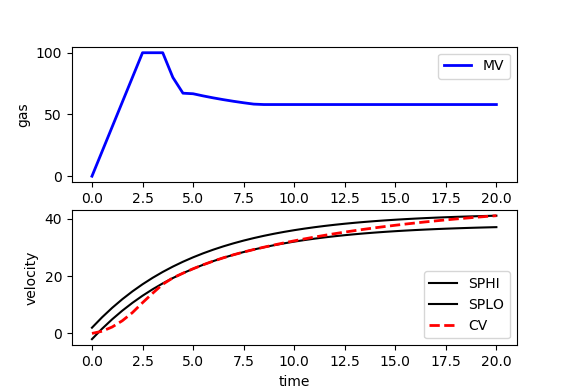
from random import random
from gekko import GEKKO
import matplotlib.pyplot as plt
# initialize GEKKO model
m = GEKKO()
# time
m.time = np.linspace(0,20,41)
# constants
mass = 500
# Parameters
b = m.Param(value=50)
K = m.Param(value=0.8)
# Manipulated variable
p = m.MV(value=0, lb=0, ub=100)
# Controlled Variable
v = m.CV(value=0,name='v')
# Equations
m.Equation(mass*v.dt() == -v*b + K*b*p)
m.options.IMODE = 6 # control
# MV tuning
p.STATUS = 1 #allow optimizer to change
p.DCOST = 0.1 #smooth out MV
p.DMAX = 20 #slow down change of MV
# CV tuning
v.STATUS = 1 #add the CV to the objective
m.options.CV_TYPE = 1 #Dead-band
v.SPHI = 42 #set point
v.SPLO = 38 #set point
v.TR_INIT = 1 #setpoint trajectory
v.TAU = 5 #time constant of setpoint trajectory
# Solve
m.solve()
# get additional solution information
import json
with open(m.path+'//results.json') as f:
results = json.load(f)
# Plot solution
plt.figure()
plt.subplot(2,1,1)
plt.plot(m.time,p.value,'b-',lw=2,label='MV')
plt.legend(loc='best')
plt.ylabel('gas')
plt.subplot(2,1,2)
plt.plot(m.time,results['v.tr_lo'],'k-',label='SPHI')
plt.plot(m.time,results['v.tr_hi'],'k-',label='SPLO')
plt.plot(m.time,v.value,'r--',lw=2,label='CV')
plt.legend(loc='best')
plt.ylabel('velocity')
plt.xlabel('time')
plt.show()
Two common objective functions are shown below as squared error and l1-norm forms1.
Squared Error Objective
The squared error objective is the most common form used in the literature. It penalizes deviation of the current measured value of the controlled variable from the desired target value.
$$\min_{x,y,u} \Phi = \left(y-y_t\right)^T W_t \left(y-y_t\right) + y^T w_y + u^T w_u + \Delta u^T W_{\Delta u} \Delta u$$
$$\mathrm{subject\;\;to}$$
$$0 = f\left(\frac{dx}{dt},x,y,u\right)$$
$$0 \le g\left(\frac{dx}{dt},x,y,u\right)$$
$$\tau_c \frac{dy_t}{dt} + y_t = sp$$
l1-norm Objective
The l1-norm objective is the absolute value of the difference between the current measured value of the controlled variable and the desired target value. The absolute value operator (abs(x)) does not have a continuous first and second derivative at x=0 (see absolute value function alternatives). Slack variables give the same absolute value function but with continuous first and second derivatives.
$$\min_{x,y,u} \Phi = w_{hi}^T e_{hi} + w_{lo}^T e_{lo} + y^T w_y + u^T w_u + w_{\Delta u}^T \left(\Delta u_U+\Delta u_L\right)$$
$$\mathrm{subject\;\;to}$$
$$0 = f\left(\frac{dx}{dt},x,y,u\right)$$
$$0 \le g\left(\frac{dx}{dt},x,y,u\right)$$
$$\tau_c \frac{dy_{t,hi}}{dt} + y_{t,hi} = sp_{hi}$$
$$\tau_c \frac{dy_{t,lo}}{dt} + y_{t,lo} = sp_{lo}$$
$$e_{hi} \ge y - y_{t,hi}$$
$$e_{lo} \ge y_{t,lo} - y$$
$$\Delta u_U \ge u_i - u_{i-1}$$
$$\Delta u_L \ge u_{i-1} - u_i$$
$$e_{hi}, e_{lo}, \Delta u_U, \Delta u_L \ge 0$$
Nomenclature
$$\Phi=\mathrm{Objective\,Function}$$
$$y=\mathrm{model\,predictions}$$
$$y_t,y_{t,hi},y_{t,lo}=\mathrm{reference\,trajectory\,or\,range}$$
$$W_t,w_{hi}, w_{lo}=\mathrm{penalty\,outside\,reference\,trajectory\,(WSP,WSPHI,WSPLO)}$$
$$W_{\Delta u}, w_{\Delta u}=\mathrm{manipulated\,variable\,movement\,penalty\,(DCOST)}$$
$$w_{u}, w_{y}=\mathrm{weight\,on\,input\,and\,output\,(COST)}$$
$$y,x,u=\mathrm{outputs,\,states,\,and\,inputs}$$
$$\Delta u=\mathrm{manipulated\,variable\,change}$$
$$f,g=\mathrm{equality\,and\,inequality\,constraints}$$
$$e_{hi},e_{lo}=\mathrm{upper\,and\,lower\,error\,outside\,dead-band}$$
$$\Delta u_U,\Delta u_L=\mathrm{upper\,and\,lower\,manipulated\,variable\,change}$$
In formulating an objective function and model equations follow the following tips for improved convergence.
- Rearrange to equation in residual form to:
- Avoid divide by zero
- Minimize use of functions like sqrt, log, exp, etc.
- Have continuous first and second derivatives
- Fit the equation into a linear or quadratic form
- Bounds
- Include variable bounds to exclude infeasible solutions
- Variable bounds to avoid regions of strong nonlinearity
- Caution: watch for infeasible solutions
- Scaling:
- Scale absolute value of variables to 1e-3 to 1e3
- Scale absolute value of equation residuals to 1e-3 to 1e3
- Better that 1st derivative values are closer to 1.0
- Good initial conditions:
- Starting near a solution can improve convergence
- Try multiple initial conditions to verify global solution (non-convex problems)
- Explicitly calculate intermediate values
- Check iteration summary for improved convergence
Custom Reference Trajectory
Some applications require a custom reference trajectory that does not fit a standard form. A custom reference trajectory is specified by creating a new error (e) variable that is the difference between the specified trajectory (sinusoidal, sawtooth, random, etc) and the model output. This error is specified as a controlled variable (CV) with an upper and lower dead-band denoted as SPHI and SPLO. The CV can also be a value of zero with a squared error objective (e.SP=0, m.options.CV_TYPE=2) to drive to a target instead of a dead-band range.
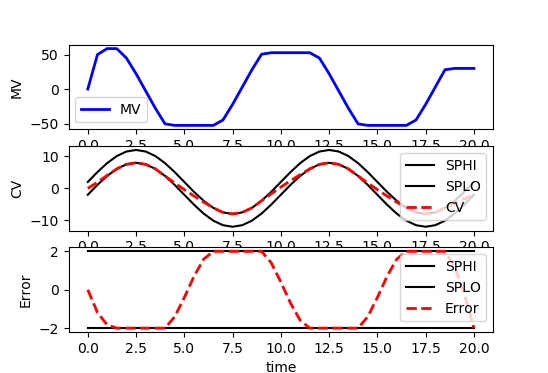
from random import random
from gekko import GEKKO
import matplotlib.pyplot as plt
# initialize GEKKO model
m = GEKKO()
# time
m.time = np.linspace(0,20,41)
# constants
mass = 500
# Parameters
b = m.Param(value=50)
K = m.Param(value=0.8)
# Manipulated variable
p = m.MV(value=0, lb=-100, ub=100)
# Reference trajectory
sine = 10*np.sin(m.time/20*4*np.pi)
traj = m.Param(value=sine)
# Controlled Variable
v = m.SV(value=0,name='v')
# Error
e = m.CV(value=0,name='e')
# Equations
m.Equation(mass*v.dt() == -v*b + K*b*p)
m.Equation(e==v-traj)
m.options.IMODE = 6 # control
# MV tuning
p.STATUS = 1 #allow optimizer to change
p.DCOST = 0.1 #smooth out MV
p.DMAX = 50 #slow down change of MV
# CV tuning
e.STATUS = 1 #add the CV to the objective
m.options.CV_TYPE = 1 #Dead-band
db = 2
e.SPHI = db #set point
e.SPLO = -db #set point
e.TR_INIT = 0 #setpoint trajectory
e.TAU = 5 #time constant of setpoint trajectory
# Solve
m.solve()
# get additional solution information
import json
with open(m.path+'//results.json') as f:
results = json.load(f)
# Plot solution
plt.figure(figsize=(6,4))
plt.subplot(3,1,1)
plt.plot(m.time,p.value,'b-',lw=2,label='MV')
plt.legend(loc='best')
plt.ylabel('MV')
plt.subplot(3,1,2)
plt.plot(m.time,sine+db,'k-',label='SPHI')
plt.plot(m.time,sine-db,'k-',label='SPLO')
plt.plot(m.time,v.value,'r--',lw=2,label='CV')
plt.legend(loc='best')
plt.ylabel('CV')
plt.subplot(3,1,3)
plt.plot(m.time,results['e.tr_hi'],'k-',label='SPHI')
plt.plot(m.time,results['e.tr_lo'],'k-',label='SPLO')
plt.plot(m.time,e.value,'r--',lw=2,label='Error')
plt.legend(loc='best')
plt.ylabel('Error')
plt.xlabel('time')
plt.tight_layout()
plt.show()
References
- Hedengren, J. D. and Asgharzadeh Shishavan, R., Powell, K.M., and Edgar, T.F., Nonlinear Modeling, Estimation and Predictive Control in APMonitor, Computers and Chemical Engineering, Volume 70, pg. 133–148, 2014. Article