LLM with Ollama Python Library


The ollama and transformers libraries are two packages that integrate Large Language Models (LLMs) with Python to provide chatbot and text generation capabilities. This tutorial covers the installation and basic usage of the ollama library.
The first step is to install the ollama server. After the server is running, install the ollama python package with pip:
With the ollama server and python package installed, retrieve the mistral LLM or any of the available LLM models in the ollama library. The mistral model is a relatively small (7B parameter) LLM that can run on most CPUs. Larger models such as the mixtral model work best on GPUs with sufficient processing power and VRAM memory.
ollama.pull('mistral')
The ollama and LLM model installation occurs once. List the available models.
With the model installed, use the generate function to send a prompt to the LLM and print the response.
q = 'How can LLMs be used in engineering?'
ollama.generate(model='mistral', prompt=q)
The chat function retains memory of prior prompts while the generate function does not.
prompt1 = 'What is the capital of France?'
response = ollama.chat(model='mistral', messages=[
{'role': 'user','content': prompt1,},])
r1 = response['message']['content']
print(r1)
prompt2 = 'and of Germany?'
response = ollama.chat(model='mistral', messages=[
{'role': 'user','content': prompt1,},
{'role': 'assistant','content': r1,},
{'role': 'user','content': prompt2,},])
r2 = response['message']['content']
print(r2)
The responses are:
🗣️ The capital city of France is Paris. Paris is one of the most famous cities in the world and is known for its iconic landmarks such as the Eiffel Tower, the Louvre Museum, Notre-Dame Cathedral, and the Champs-Élysées. It is also home to many important cultural institutions and is a major European political, economic, and cultural center.
🗣️ The capital city of Germany is Berlin. Berlin is the largest city in Germany by both area and population, and it is one of the most populous cities in the European Union. It is located in northeastern Germany and serves as the seat of government and the main cultural hub for the country. Berlin is known for its rich history, diverse culture, and numerous landmarks including the Brandenburg Gate, the Reichstag Building, and the East Side Gallery.
The ollama library also supports streaming responses so that the text appears in pieces as it is generated instead of printed once after completion. This improves the perceived responsiveness of the LLM, especially with limited computing resources.
prompt = 'How can LLMs improve automation?'
stream = ollama.chat(model='mistral',
messages=[{'role': 'user', 'content': prompt}],
stream=True,)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
The library API is designed to access the ollama REST API with functions like chat, generate, list, show, create, copy, delete, pull, push, and embeddings.
Applications in Engineering
The ollama python library facilitates LLMs in applications such as chatbots, customer support agents, and content generation tools. Code generation, debugging, and cross-language programming support can be accelerated with LLMs if used effectively. The ollama library simplifies interaction with advanced LLM models enabling more sophisticated responses and capabilities.
One potential obstacle to using more sophisticated models is the size of the LLM and speed of response without a high-end GPU. Cloud computing resources are a viable option for application deployment.

Activity: Evaluate Model Performance
It is important to understand the trade-offs for quality, cost, and speed for different LLMs. There are AI model websites that benchmark model performance and service providers.
The purpose of this exercise is to compare model performance on your computer. Install 3 different models on your local ollama server. Test the speed of response versus the size of the model with the script below.
import pandas as pd
import matplotlib.pyplot as plt
# question
q = '''How can data science techniques improve predictive maintenance
of rotating equipment such as pumps and turbines?'''
# context
cntx = '''In engineering, particularly in industries such as manufacturing,
transportation, and energy, machinery and equipment are crucial assets.
These assets require regular maintenance to ensure optimal performance
and to prevent unexpected breakdowns, which can be costly and disruptive.
Traditional maintenance strategies often rely on scheduled maintenance
routines or responding to equipment failures as they occur. However,
with the advancement of data science techniques such as machine learning
and predictive analytics, engineers can now predict when a machine is
likely to fail or require maintenance. This approach, known as predictive
maintenance, uses historical data, sensor data, and algorithms to identify
patterns and predict potential issues before they happen. The implementation
of these data science techniques in engineering maintenance can lead to
more efficient use of resources, reduced downtime, and potentially
significant cost savings.'''
# models
models = ['phi','mistral','gemma'] #,'mixtral']
# store results
r = []
idx = []
# prompt without context
pmpt = f'Question: {q}'
for i,mx in enumerate(models):
r.append(ollama.generate(model=mx, prompt=pmpt))
idx.append(mx)
print(f"Model: {idx[-1]}, Time: {r[-1]['total_duration']/1e9}s")
# prompt with context
pmpt = f'Context: {cntx} Question: {q}'
for i,mx in enumerate(models):
r.append(ollama.generate(model=mx, prompt=pmpt))
idx.append(mx+'+ctx')
print(f"Model: {idx[-1]}, Time: {r[-1]['total_duration']/1e9}s")
# put results in DataFrame
rcols = ['total_duration','load_duration',
'prompt_eval_count','eval_count',
'prompt_eval_duration','eval_duration']
data = {}
for i,x in enumerate(rcols):
if (i==2) or (i==3):
data[x] = [ri[x] for ri in r]
else:
data[x] = [ri[x]/1e9 for ri in r]
data = pd.DataFrame(data, index=idx)
data['calc_duration'] = data['total_duration']-data['load_duration']
data['prompt_rate'] = data['prompt_eval_count']/data['prompt_eval_duration']
data['eval_rate'] = data['eval_count']/data['eval_duration']
print(data)
pcols = ['load_duration','prompt_rate','eval_rate']
axs = data[pcols].plot(figsize=(6,5),kind='bar',subplots=True)
ylb = ['Time (s)','Rate (tk/s)','Rate (tk/s)']
for i,ax in enumerate(axs):
ax.set_title('')
ax.set_ylabel(ylb[i])
plt.tight_layout(); plt.savefig('results.png',dpi=300); plt.show()
Include additional models for more capable GPUs such as adding the mixtral model.
Sample results are shown below for an NVIDIA RTX3070 GPU with 8 GB VRAM:
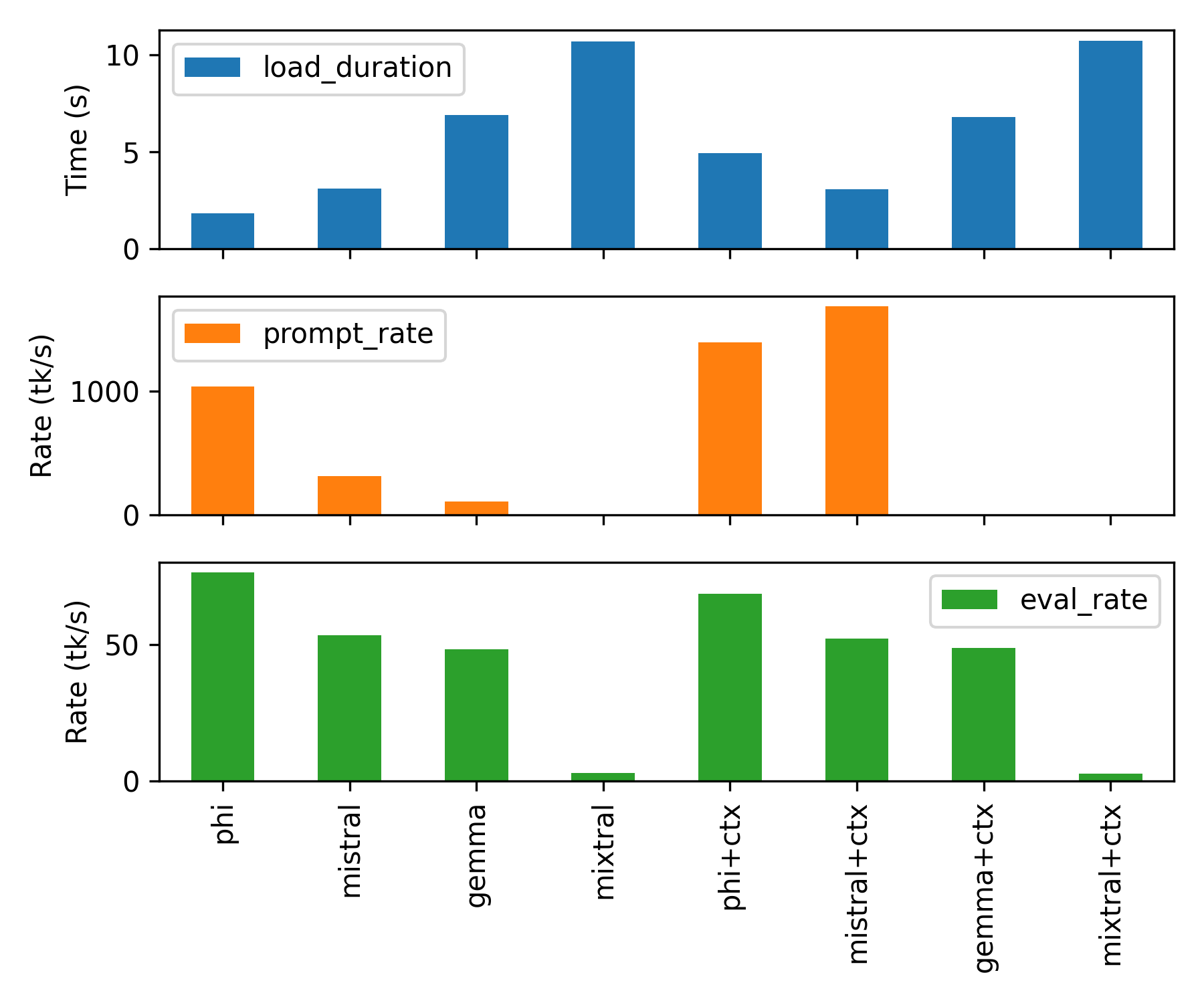
and on an NVIDIA RTX3090 GPU with 24 GB VRAM:
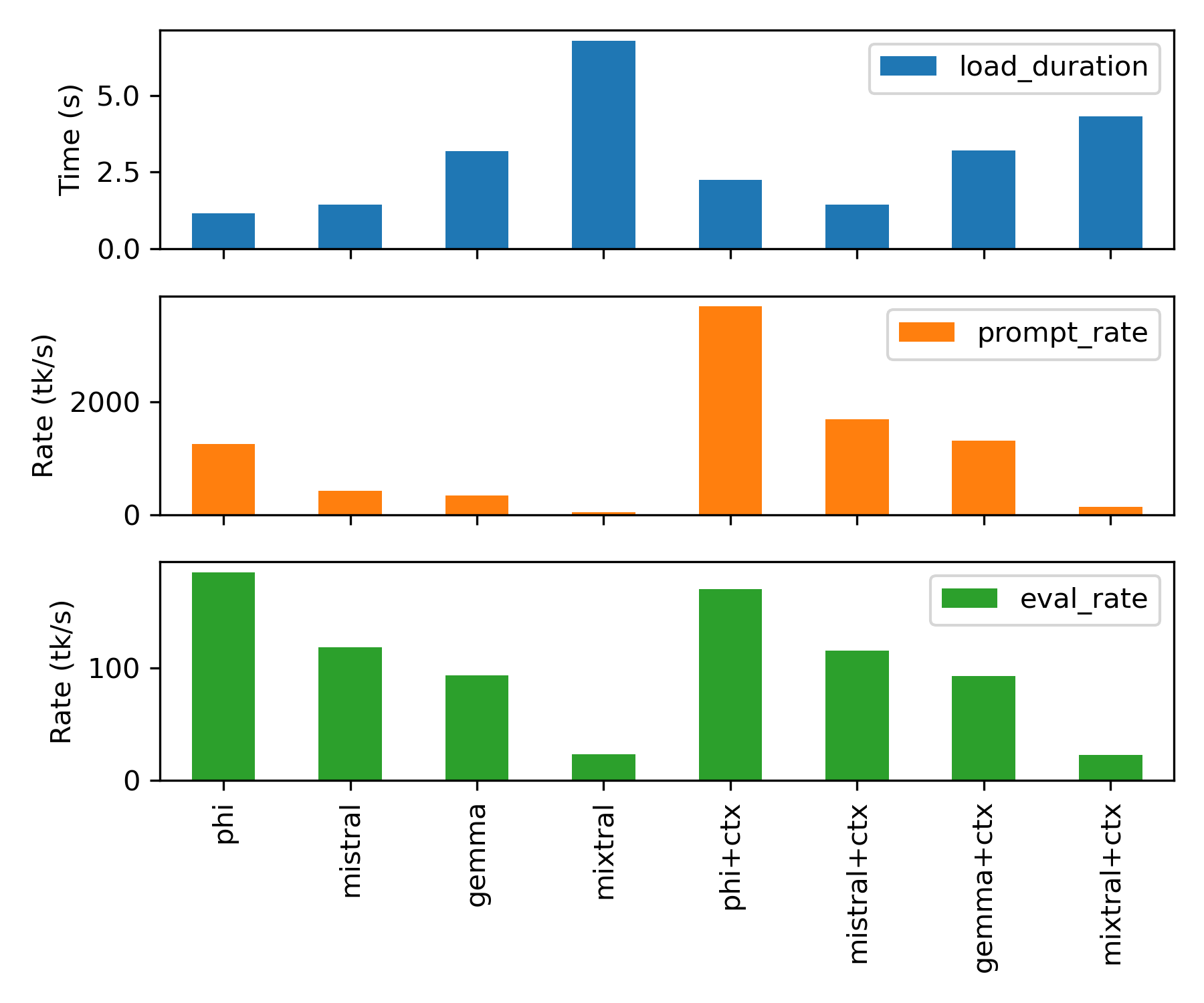
Additional information such as the model size and total time of each evaluation is shown below.
GPU NVIDIA RTX3070 NVIDIA RTX3090
CUDA cores 5888 10496
8GB VRAM 24GB VRAM
phi (1.6GB) 4.30 s 1.56 s
mistral (4.1GB) 12.24 s 5.54 s
gemma (5.2GB) 18.13 s 9.00 s
mixtral (26GB) 159.47 s 30.47 s
phi+ctx (4.1GB) 14.51 s 7.20 s
mistral+ctx (5.2GB) 12.71 s 5.18 s
gemma+ctx 140.17 s 7.67 s
mixtral+ctx (26GB) 1087.29 s 30.34 s
The prompt evaluation speed and output evaluation speed significantly decrease when the model is larger than the GPU VRAM. When the model fits in VRAM, the time scales approximately by number of CUDA cores. The RTX3090 has almost twice the number of CUDA cores as the RTX3070 GPU and the total time is approximately half for the smaller models.
